一致性模型概述
一致性模型是分布式系统中对数据读写操作顺序和结果的约定。不同的一致性模型定义了在不同情况下系统对数据的一致性保证程度。而其之所以这么重要正是因为其复杂而又直接关系到一个分布式系统的正确性,所以值得被反复讨论。
在开发单机多线程程序的时候,不同线程如果不加任何措施同时对同一片内存进行操作会冲突造成不可预知的后果。分布式系统同样是个并发系统,这个问题依旧,不同的结点同时对同一个数据进行修改同样会造成不可预知的后果,造成数据一致性被破坏,同时加上分布式系统中可用性和性能等因素,使得这一问题更加棘手。
对于并发操作来说,其实本质上是一个顺序的操作序列,只是不同进程的操作被交织在了一起,而一致性模型就是用于判断这个操作序列是否合法。因此,一致性模型其实就是一种约定,如果一个系统声称满足某个一致性模型,那么它就保证了在一定条件下,对于数据的读写操作都是可预期的。
这边引用 Jepson 的一张关于一致性模型的图
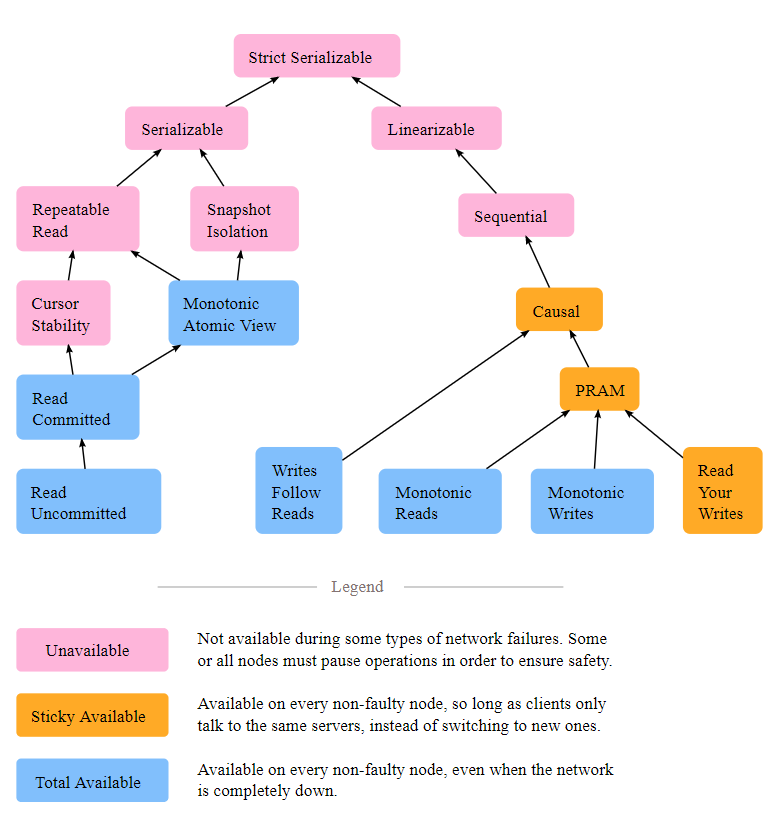
这张图中,从下往上,模型对于操作序列的要求更严格,称为更强(stronger)的一致性模型,反之要求则更宽松,称为更弱(weaker)。而箭头 A->B 则表示满足 B 则一定满足 A,也就是说满足 B 的操作是满足 A 的操作的一个子集。
根据 CAP 理论,当追求 C 时势必需要放弃 A 或 P。如果发生了网络错误,图中红色的表示必须暂停服务,黄色的表示客户端仍可以继续在同一个未发生错误的结点上继续工作,蓝色的表示即使网络完全错误,仍可以切换至正常的结点上继续工作。
在对每个模型进行介绍之前,还需先明确最理想的状态是怎么样的,也就是一致性模型所需要保证的目标。最强的一致性模型自然是图中位于最上方的 Strict Serializability。其实说来简单,就是单机执行的状态,所有事务的子操作不交错,根据实际发生的次序顺序执行。这其实正好对应了图中指向它的 Serializability 和 Linearizable,背后其实对应的是 隔离性(数据库事务 ACID 中的 I)和一致性(分布式系统 CAP 的 C)。
隔离性
隔离性指的是各个事务执行过程相互隔离,防止并发执行导致数据不一致。在解释各个隔离性的模型之前,让我们首先看看少了隔离性会遇到什么样的问题。
潜在的问题
P0 Dirty Write
Dirty Write 就是一个事务修改了另一个尚未提交的事务已经修改的值,如下
+------+-------+-------+-------+-------+
| T1 | Wx(1) | | | Wy(1) |
+------+-------+-------+-------+-------+
| T2 | | Wx(2) | Wy(2) | |
+------+-------+-------+-------+-------+
| x(0) | 1 | 2 | 2 | 2 |
+------+-------+-------+-------+-------+
| y(0) | 0 | 0 | 2 | 1 |
+------+-------+-------+-------+-------+
T2 的 Wx(2) 覆盖了 T1 的 Wx(1),造成该修改的丢失。
P1 Dirty Read
Dirty Read 指一个事务读取到了另一个执行到一半的事务中修改的值,如下
+-------+--------+--------+--------+--------+
| T1 | Wx(40) | | | Wy(60) |
+-------+--------+--------+--------+--------+
| T2 | | Rx(10) | Ry(50) | |
+-------+--------+--------+--------+--------+
| x(50) | 40 | 10 | 10 | 10 |
+-------+--------+--------+--------+--------+
| y(50) | 50 | 50 | 50 | 60 |
+-------+--------+--------+--------+--------+
假设原本 x 与 y 存款均为50,现在 T1 负责 x 向 y 转账 10,T2 负责读取 x 和 y 的存款。那么无论如何转账,两人存款之和必定是 100,Dirty Read 使得这一约束无法得到保证。
P2 Non-Repeatable Read
Non-Repeatable Read 也称 Fuzzy Read,指一个事务读取过程中读到了另一个事务更新后的结果,如下
+-------+--------+--------+--------+--------+
| T1 | Rx(50) | | | Ry(60) |
+-------+--------+--------+--------+--------+
| T2 | | Wx(40) | Wy(60) | |
+-------+--------+--------+--------+--------+
| x(50) | 50 | 40 | 40 | 40 |
+-------+--------+--------+--------+--------+
| y(50) | 50 | 50 | 60 | 60 |
+-------+--------+--------+--------+--------+
同样转账的例子,T1 读取到一半时插入 T2 的更新操作,导致约束条件再次被破坏。
P3 Phantom
Phantom 指的是某一事务 A 先挑选出了符合一定条件的数据,之后另一个事务 B 修改了符合该条件的数据,此时 A 再进行的操作都是基于旧的数据,从而产生不一致,例如
+----------------+--------+-----------+-----------+-----------+
| T1 | {a, b} | | | R(3) |
+----------------+--------+-----------+-----------+-----------+
| T2 | | W(c) | W(3) | |
+----------------+--------+-----------+-----------+-----------+
| Employees | {a, b} | {a, b, c} | {a, b, c} | {a, b, c} |
+----------------+--------+-----------+-----------+-----------+
| Employee Count | 2 | 2 | 3 | 3 |
+----------------+--------+-----------+-----------+-----------+
T1 前后两次读由于 T2 的存在打破了约束,使得两次读的结果不一致。
P4 Lost Update
Lost Update 指的是更新被另一个事务覆盖,例如
1
2
3
4
5
6
7
+--------+-----+---------+---------+
| T1 | | | Wx(110) |
+--------+-----+---------+---------+
| T2 | | Wx(120) | |
+--------+-----+---------+---------+
| x(100) | 100 | 120 | 110 |
+--------+-----+---------+---------+
T2 执行于 T1 执行过程中间,两个事务之间并没有发生任何 Dirty Read,但 T2 的更新被丢失了,相当于并没有被执行。
P4C Cursor Lost Update
Cursor Lost Update 与前者类似,只是发生于 cursor 的操作过程之中,例如
1
2
3
4
5
6
7
+--------+----------+---------+----------+
| T1 | RCx(100) | | Wx(110) |
+--------+----------+---------+----------+
| T2 | | Wx(75) | |
+--------+----------+---------+----------+
| x(100) | 100 | 75 | 110 |
+--------+----------+---------+----------+
RCx 表示通过 cursor 读取,这样导致 T2 的更新操作被丢失了。
A5A Read Skew
Read Skew 由于事务的交叉导致读取到了不一致的数据,例如转账的例子
+-------+--------+--------+--------+--------+
| T1 | Rx(50) | | | Ry(75) |
+-------+--------+--------+--------+--------+
| T2 | | Wx(25) | Wy(75) | |
+-------+--------+--------+--------+--------+
| x(50) | 50 | 25 | 25 | 25 |
+-------+--------+--------+--------+--------+
| y(50) | 50 | 50 | 75 | 75 |
+-------+--------+--------+--------+--------+
A5B Write Skew
Write Skew 指两个事务同时读取到了一致的数据,然后分别进行了满足条件的修改,但最终结果破坏了一致性,例如
+-------+--------+--------+--------+--------+
| T1 | Rx(30) | Ry(10) | Wy(60) | |
+-------+--------+--------+--------+--------+
| T2 | Rx(30) | Ry(10) | | Wx(50) |
+-------+--------+--------+--------+--------+
| x(30) | 30 | 30 | 30 | 50 |
+-------+--------+--------+--------+--------+
| y(10) | 10 | 10 | 60 | 60 |
+-------+--------+--------+--------+--------+
要求 x+y <= 100,T1 和 T2 都读取到了符合条件的数据,并在要求范围内修改了数据,但最后结果破坏了约束。
隔离级别
想要避免上述问题,付出的代价是不同的。为了确定上述情况是否会发生,同时能够根据场景选择付出怎么样的代价,因此产生了隔离级别这一概念,用于指明可能发生的问题,共有如下数种隔离级别:
- Read Uncommitted:事务执行过程中能够读到未提交的修改。
- Read Committed:事务执行过程中能够读到已提交的修改。
- Cursor Stability:使用 cursor 读取某个数据时,这个不能被其他事务修改直至 cursor 释放或事务结束。
- Monotonic Atomic View:在 Read Committed 的基础上加上了原子性的约束,观测到其他事务的修改时会观察到完整的修改。
- Repeatable Read:即使其他事务修改了数据,重复读取都会读到一样的数据。
- Snapshot:每个事务在独立、一致的 snapshot 上进行操作,直至提交后其他事务才可见。
- Serializable:事务按照一定的次序顺序执行。
对应的可能发生的问题如下
P0
P1
P4C
P4
P2
P3
A5A
A5B
Read Uncommitted
NP
P
P
P
P
P
P
P
Read Committed
NP
NP
P
P
P
P
P
P
Cursor Stability
NP
NP
NP
SP
SP
P
P
SP
Repeatable Read
NP
NP
NP
NP
NP
P
NP
NP
Snapshot
NP
NP
NP
NP
NP
SP
NP
P
Serializable
NP
NP
NP
NP
NP
NP
NP
NP
NP(Not Possible):不可能发生
SP(Sometimes Possible):有时候可能发生
P(Possible):会发生
MySQL 中只采用了 Read Uncommitted、Read Committed、Repeatable Read、Serializable 四种级别。
一致性
隔离性并不保证其他节点看到数据的顺序,这一点由一致性来进行保证。一致性指的是所有结点都能访问到最新的数据副本,并因此衍生出了不同级别的一致性,以表示所能看到的数据发生的顺序。
强一致性(Strong Consistency):
严格串行化(Strict Serializability):
定义:所有操作都可以看作是按照某个全局的、线性的顺序执行的,且每个操作的效果立刻对后续操作可见。
应用场景:强一致性要求很高的系统,如银行交易系统。
线性化(Linearizability):
定义:每个操作在某个点上“原子的”发生,且这个点必须在操作开始和结束之间。
应用场景:需要保证最新写入立刻对所有后续读可见的系统,如某些分布式数据库和文件系统。
弱一致性(Weak Consistency):
最终一致性(Eventual Consistency):
定义:如果没有新的更新操作,系统最终会达到一致状态,即所有副本的数据最终会收敛到相同的状态。
应用场景:高可用性和性能要求高的系统,如 DNS、CDN 等。
因果一致性(Causal Consistency):
定义:如果一个操作影响了另一个操作,那么前一个操作的结果必须在后一个操作之前可见。
应用场景:需要保证因果关系的系统,如社交网络中的动态更新。
序列一致性(Sequential Consistency):
定义:所有操作按照某个顺序执行,但这个顺序不必与实际时间顺序一致,只需对所有进程可见的顺序一致。
应用场景:需要保证全局操作顺序一致性的系统,如某些分布式存储系统。
弱化的隔离级别:
读已提交(Read Committed):
定义:只能读取已经提交的数据,但不同事务之间的操作顺序不一定一致。
应用场景:数据库系统中,读已提交是一个常见的隔离级别。
可重复读(Repeatable Read):
定义:在同一事务内多次读取同一数据项,结果必须一致。
应用场景:需要避免“不可重复读”问题的系统,如某些事务处理系统
- Writes Follow Reads:如果一个进程读到了操作 w1 修改的值,并之后执行了操作 w2,那么 w2 只有在 w1 后可见,也就是说如果看到了 w2 那么一定看到了 w1。
- Monotonic Reads:如果一个进程进行了读取 r1,再进行 r2,那么 r2 不可能看到 r1 发生前的数据。
- Monotonic Writes:如果一个进程进行了写入 w1,再进行 w2,那么其他进程都会看到 w1 发生于 w2 之前。
- Read Your Writes:如果一个进程进行了写入 w,再进行读取 r,那么 r 一定能看到 w 所进行的修改。
- PRAM (Pipeline Random Access Memory):单进程的写操作被观察到都是顺序的,不同进程间的写操作被观察到的顺序则可能不同。PRAM = Monotonic Writes + Monotonic Reads + Read Your Writes.
- Casual:存在因果关系的操作在任何地方被观察的顺序是一致的。
- Sequential:保证操作一定按一定顺序发生,且任何地方观测到的都是一致的。
- Linearizable:所有操作都按操作发生的时间顺序原子地发生。


