在现代计算机系统中,I/O 操作是影响性能的关键因素,尤其是在网络服务和本地存储密集型应用中。你是否曾经思考过网络 I/O 和本地 I/O 之间的性能差异?为什么网络传输总是比本地硬盘慢?
函数select()、poll()和epoll()在网络编程和操作系统中用于监视多个文件描述符,以查看其中任何一个是否可进行 I/O(例如,套接字已准备好进行读/写)。这些主要用于事件驱动编程,特别是在服务器中同时处理多个连接时。那么,epoll 到底为什么如此高效?它如何超越传统的 select() 和 poll()?通过这篇讨论,你将深入了解为什么 epoll 是大规模网络 I/O 管理的首选,以及如何在实践中最大化其优势。
在操作系统中,程序运行的空间分为内核空间和用户空间, 用户空间所有对io操作的代码(如文件的读写、socket的收发等)都会通过系统调用进入内核空间完成实际的操作。
阻塞 I/O
在阻塞 I/O 模式下,系统调用(如 read() 或 recvfrom())会一直等待,直到内核把数据准备好并传输到用户空间。此期间,线程会被挂起,CPU将被释放去做其他事情,但这个线程无法执行任何其他任务,直到 I/O 操作完成。这种情况会导致线程阻塞,尤其在高并发环境下,每个 I/O 操作都可能耗费大量时间等待。在linux中,默认情况下所有的socket都是阻塞的,一个典型的读操作流程大概是这样: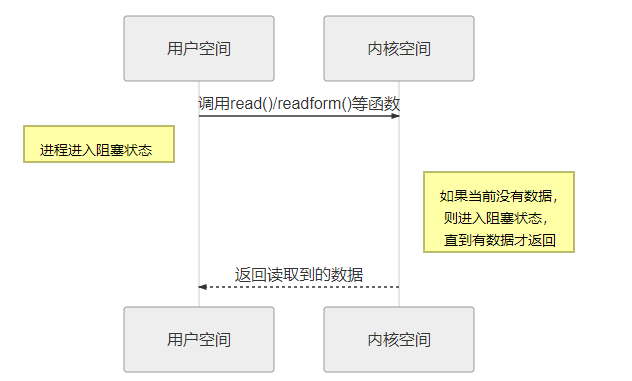
当用户进程调用了 read()/recvfrom() 等系统调用函数,它会进入内核空间中,当这个网络I/O没有数据的时候,内核就要等待数据的到来,而在用户进程这边,整个进程会被阻塞,直到内核空间返回数据。当内核空间的数据准备好了,它就会将数据从内核空间中拷贝到用户空间,此时用户进程才解除阻塞的的状态,重新运行起来。
所以,阻塞I/O的特点就是在IO执行的两个阶段(用户空间与内核空间)都被阻塞了。
非阻塞 I/O
非阻塞 I/O 则允许程序发起 I/O 操作(例如 read() 或 recvfrom()),即使数据还没准备好,内核也不会让进程挂起,而是立即返回。此时用户进程得到的是一个错误,提示数据尚未准备好。用户进程需要不断轮询,重复调用 I/O 操作直到数据可用。这种方式避免了线程被阻塞的情况,但频繁的轮询可能会导致 CPU 使用效率低下。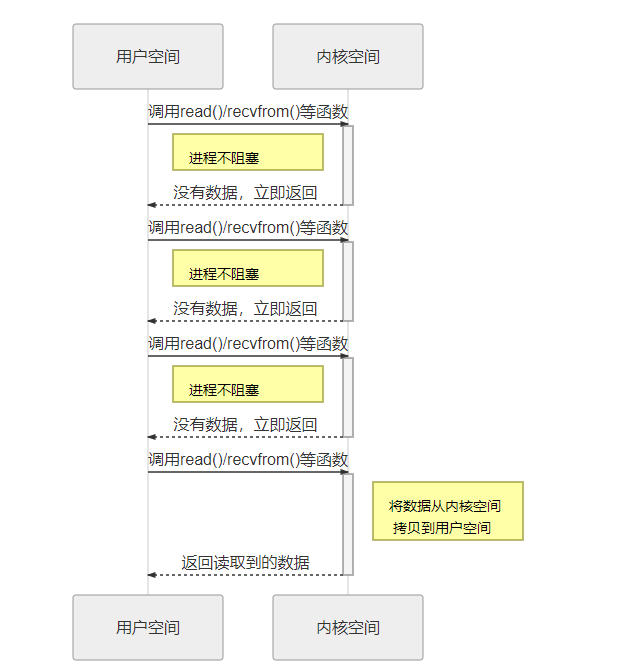
多路复用 I/O
多路复用 I/O (select(),poll(),epoll()) 允许单个线程监控多个文件描述符(如 socket),从而在多个 I/O 操作之间进行复用。它的基本原理是通过轮询多个 socket,查看是否有数据到达,并在有数据到达时通知应用程序。相比非阻塞 I/O,这种机制更高效,特别适合于处理大量连接的服务器。
本地 I/O 操作通常为阻塞模式,即在进行 I/O 操作时,进程会被挂起直到操作完成。然而,现代操作系统也提供了非阻塞本地 I/O 或异步 I/O(如 Linux 的 aio 或 Windows 的 IOCP),允许应用程序继续执行其他任务而不等待 I/O 完成。网络 I/O 同样可以是阻塞的或非阻塞的。在非阻塞网络 I/O 中,进程发起 I/O 操作时不需要等待数据返回,可以继续执行其他操作。网络 I/O 领域中,异步 I/O、多路复用 I/O(如 select()、poll()、epoll())、以及事件驱动编程(如 libuv、libevent)等技术被广泛使用,以应对高延迟和并发问题。
将协程与IO多路复用结合起来,可以实现高性能的并发IO程序。
socket 是 Unix 中的术语。socket 可以用于同一台主机的不同进程间的通信,也可以用于不同主机间的通信。一个 socket 包含地址、类型和通信协议等信息,通过 socket() 函数创建:int socket(int domain, int type, int protocol)返回的就是这个 socket 对应的文件描述符 fd。操作系统将 socket 映射到进程的一个文件描述符上,进程就可以通过读写这个文件描述符来和远程主机通信。
可以这样理解:socket 是进程间通信规则的高层抽象,而 fd 提供的是底层的具体实现。socket 与 fd 是一一对应的。通过 socket 通信,实际上就是通过文件描述符 fd 读写文件。这也符合 Unix“一切皆文件”的哲学。使用IO多路复用技术监听多个socket,当有socket可读或可写时,通过事件通知,激活相应的协程进行处理。
举个最直接的例子:Go 语言
Go 的协程(goroutine)模型是一个典型代表:
1 | func handler(conn net.Conn) { |
表面上好像每个 conn 都是阻塞读写的,但实际上:
-
Go runtime 在底层为每个 socket 注册到 epoll;
-
当 goroutine 调用
Read()时,如果没有数据可读,它会:- 把当前 goroutine 状态挂起;
- 把 fd 注册到 epoll;
- 调度其他 goroutine;
- 当 epoll 返回“可读事件”,再恢复该 goroutine。
整个过程完全用户态切换,线程没有被阻塞。所以你可以同时开 10w goroutine,因为系统线程数只维持在几十个(M:N 模型)。
Python asyncio / Node.js / Rust tokio 同理
| 框架 | 底层 I/O 多路复用 | 用户态调度机制 |
|---|---|---|
| Python asyncio | epoll/kqueue/select via selectors 模块 |
event loop 调度 coroutine |
| Node.js (libuv) | epoll/kqueue/iocp | 单线程 event loop |
| Rust tokio | epoll/kqueue/wepoll | Future + reactor 模型 |
| Go runtime | epoll/kqueue/iocp | M:N goroutine 调度器 |
这些 runtime 全都在做同一件事:
- 用 epoll 等来统一管理 I/O;
- 当协程遇到 I/O 阻塞点时,自动 yield;
- I/O 就绪后再 resume。
核心关系图(简化)
1 | 用户代码层 |
协程只是事件循环上的“任务单元”;
多路复用是驱动事件循环的“信号源”
比如 Nginx 用 epoll+回调,Go/Netty 用 epoll+协程,性能上都是百万级连接可行。
1.select()
用法:允许监视多个文件描述符,以查看它们是否已准备好读取、写入或是否有错误。
限制:
具有可监控的最大文件描述符数量(通常为 1024)。此数量由 定义FD_SETSIZE,在高并发应用程序中可能会受到限制。
当有大量文件描述符时效率低下,因为它每次都必须检查每个描述符。
使用单一数据结构来保存读取、写入和错误描述符。
例子:
fd_set readfds; FD_ZERO(&readfds); FD_SET(socket_fd, &readfds); select(socket_fd + 1, &readfds, NULL, NULL, &timeout);
2.poll()
poll 和 select 几乎没有区别。poll 在用户态通过数组方式传递文件描述符,在内核会转为链表方式存储,没有最大数量的限制 int poll(struct pollfd *fds, nfds_t nfds, int timeout);
好处:
struct pollfd使用比 使用的位掩码更具可扩展性的数组select()。引用 select 手册页:“select() 只能监视小于 FD_SETSIZE 的文件描述符数量;poll(2) 没有这个限制。”所以这可能是选择 poll 而不是 select 的一个原因。可以更轻松地处理大量文件描述符。
例子:
struct pollfd fds[2]; fds[0].fd = socket_fd; fds[0].events = POLLIN; poll(fds, 2, timeout);
3. epoll()
epoll 是 Linux 2.5.44(2002年)引入的 I/O 多路复用机制,专为高并发设计。
epoll 并非单一系统调用,而是由三个接口组成的高效事件通知机制:
epoll_create1():创建一个 epoll 实例,返回一个 epoll 文件描述符(epfd);epoll_ctl():向 epoll 实例中注册、修改或删除需要监听的 fd 及其关注的事件(如EPOLLIN、EPOLLOUT);epoll_wait():阻塞等待,直到有 fd 就绪,返回就绪事件列表。
3.1 为什么 epoll 能突破 select/poll 的性能瓶颈?
(1)内核数据结构:红黑树 + 就绪链表
-
红黑树(rb-tree):用于存储所有通过
epoll_ctl(EPOLL_CTL_ADD)注册的 fd。- 插入/删除复杂度为 O(log n),高效支持百万级连接;
- 避免了
select/poll每次调用都要从用户态拷贝整个 fd 集合到内核的问题。
-
就绪队列(ready list):一个双向链表,由内核维护。
- 当某个被监听的 fd 状态变为“可读”或“可写”时,内核会通过回调函数(callback)将该 fd 对应的
epitem节点加入就绪队列; epoll_wait()调用时,只需从该链表中取出就绪事件,无需遍历所有注册的 fd。
- 当某个被监听的 fd 状态变为“可读”或“可写”时,内核会通过回调函数(callback)将该 fd 对应的
这是 epoll 高效的核心:事件驱动 + 内核主动通知,而非用户态轮询。
(2)避免全量 fd 拷贝
select/poll:每次调用都需将整个 fd 集合从用户空间复制到内核空间;epoll:fd 只需在epoll_ctl()时注册一次,后续epoll_wait()无需传递 fd 列表,极大减少系统调用开销。
注:早期 epoll 实现曾使用
mmap共享内存加速事件传递,但现代内核已优化为高效的 ring buffer 或直接拷贝,mmap不再是必须。
(3)时间复杂度:从 O(n) 到 O(k)
-
select/poll:O(n),n 为监听的 fd 总数;这意味着即使只有少数文件描述符“就绪”(即数据可供读取/写入),内核也必须在每次调用该函数时检查每个描述符。这使得它们的性能与受监视的文件描述符数量成正比。
例如,如果您正在监视 1,000 个文件描述符,但只有 1 个已准备就绪,select()则poll()仍将对所有 1,000 个进行迭代。 -
epoll_wait():时间复杂度从 O(n) 降到 O(1) or O(k)(k 为活跃连接数); -
在 C1000K 场景下(100 万连接,仅 1000 个活跃),epoll 性能优势达 1000 倍以上。
3.2 ET(边缘触发) vs LT(水平触发)
epoll 支持两种事件触发模式,行为差异极大:
| 模式 | 行为 | 适用场景 |
|---|---|---|
| LT(Level-Triggered,默认) | 只要 fd 处于“可读”状态(即内核接收缓冲区非空),每次调用 epoll_wait() 都会返回该 fd 的事件。 |
编程简单,适合初学者;但可能重复触发,增加系统调用次数。 |
| ET(Edge-Triggered) | 仅当 fd 状态从未就绪变为就绪时(如新数据到达),才触发一次事件。若未一次性读完数据,后续 epoll_wait() 不会再次通知。 |
高性能场景;要求 fd 必须设为非阻塞模式,并在事件触发后循环读取直到返回 EAGAIN。 |
ET 模式使用示例(关键!)
1 | // 设置 socket 为非阻塞 |
⚠️ ET 模式下,若未读完数据,将永远丢失后续通知! 这是常见 bug 源头。
四、Reactor 模式:epoll 的典型应用架构
最直观的服务器处理多客户端访问的方式,就是为每个连接创建一个线程,或者更早期操作系统里甚至是一个进程。虽然线程比进程更轻量,切换成本也更低,但每连接一个线程在并发量大时仍会面临两个问题:
线程创建/销毁有系统开销(malloc stack、context switch)
线程是稀缺资源,系统线程数有上限(如 Linux 默认 1024~65535)
所以,现代服务端架构更倾向于使用线程池来复用线程资源。线程池中每个线程从任务队列中取任务处理,避免了反复创建/销毁的开销。
但线程池引入后面临另一个问题:I/O 阻塞会浪费线程资源。如果一个线程执行 read(socket) 被阻塞,而连接上没有数据,那么整个线程就"卡住"了,不能服务其他连接。
为了避免这个问题,我们可以将 socket 设置为非阻塞模式。这样 read() 不会阻塞,而是立即返回,如果没有数据,就返回错误码 EAGAIN。线程就可以在用户空间"轮询"所有 socket。
但这种方式会导致高 CPU 占用,尤其在连接数多时效率低。
Reactor(反应器)是一种事件驱动设计模式,其核心思想是:
“一个或多个输入源 → 一个事件分发器(Reactor)→ 多个事件处理器”
在 Linux 高并发服务中,epoll 就是 Reactor 的“事件分发器”。
4.1 单 Reactor 单线程(如 Redis)
- 结构:
- 1 个线程运行 epoll 事件循环;
- 所有 I/O 事件(accept、read、write)和业务逻辑均在此线程中串行处理。
- 优点:
- 无锁、无竞争,实现简单;
- 上下文切换开销为零。
- 缺点:
- 业务逻辑不能阻塞(如不能执行慢查询、sleep);
- 无法利用多核 CPU。
- 适用:I/O 密集、业务逻辑极轻的场景(如内存 KV 存储)。
4.2 单 Reactor 多线程(如早期 Nginx)
- 结构:
- 1 个主线程运行 epoll,负责监听所有 socket;
- 当连接可读/可写时,将整个连接(或请求)交给线程池处理;
- 线程池执行业务逻辑(如解析 HTTP、访问磁盘)。
- 优点:
- 利用多核;
- 业务逻辑可阻塞。
- 缺点:
- I/O 事件分发仍由单线程处理,可能成为瓶颈;
- 线程间数据传递需加锁或队列。
4.3 主从 Reactor(如 Netty、Swoole)
- 结构:
- Main Reactor(主 Reactor):仅监听
listen fd,处理accept(),将新连接分配给 Sub Reactor; - Sub Reactor(从 Reactor):每个 Sub Reactor 运行独立的 epoll 循环,管理一组连接的 I/O(read/write);
- 业务逻辑可由 Sub Reactor 自己处理,或再交给线程池。
- Main Reactor(主 Reactor):仅监听
- 优点:
- 完全并行化:accept 与 I/O 分离,I/O 与 I/O 分离;
- 无锁设计(每个连接只属于一个 Sub Reactor);
- 极致扩展性,轻松支撑百万连接。
- 关键机制:
- 使用
SO_REUSEPORT(Linux 3.9+):允许多个进程/线程 bind 同一端口,内核自动负载均衡,避免“惊群”问题; - 每个 Sub Reactor 绑定到独立 CPU 核心,减少 cache miss。
- 使用
📌 Netty 的 EventLoopGroup 就是 Sub Reactor 池的实现。
五、epoll 的局限与未来
尽管 epoll 极其成功,但它仍有局限:
- 仍是同步事件通知模型:用户需主动调用
read()/write(); - 系统调用开销仍存在(
epoll_wait+read至少两次 syscall); - 对磁盘 I/O 支持弱(更适合网络 I/O)。
下一代方案:io_uring(Linux 5.1+)
- 用户提交 I/O 请求到 ring buffer,内核异步完成;
- 支持 网络 + 文件 + epoll 替代;
- 一次 syscall 完成提交 + 获取结果;
- Redis 7.0+、Nginx、Tokio 已开始集成。
但目前,epoll + Reactor 仍是 Linux 高并发服务的事实标准。


