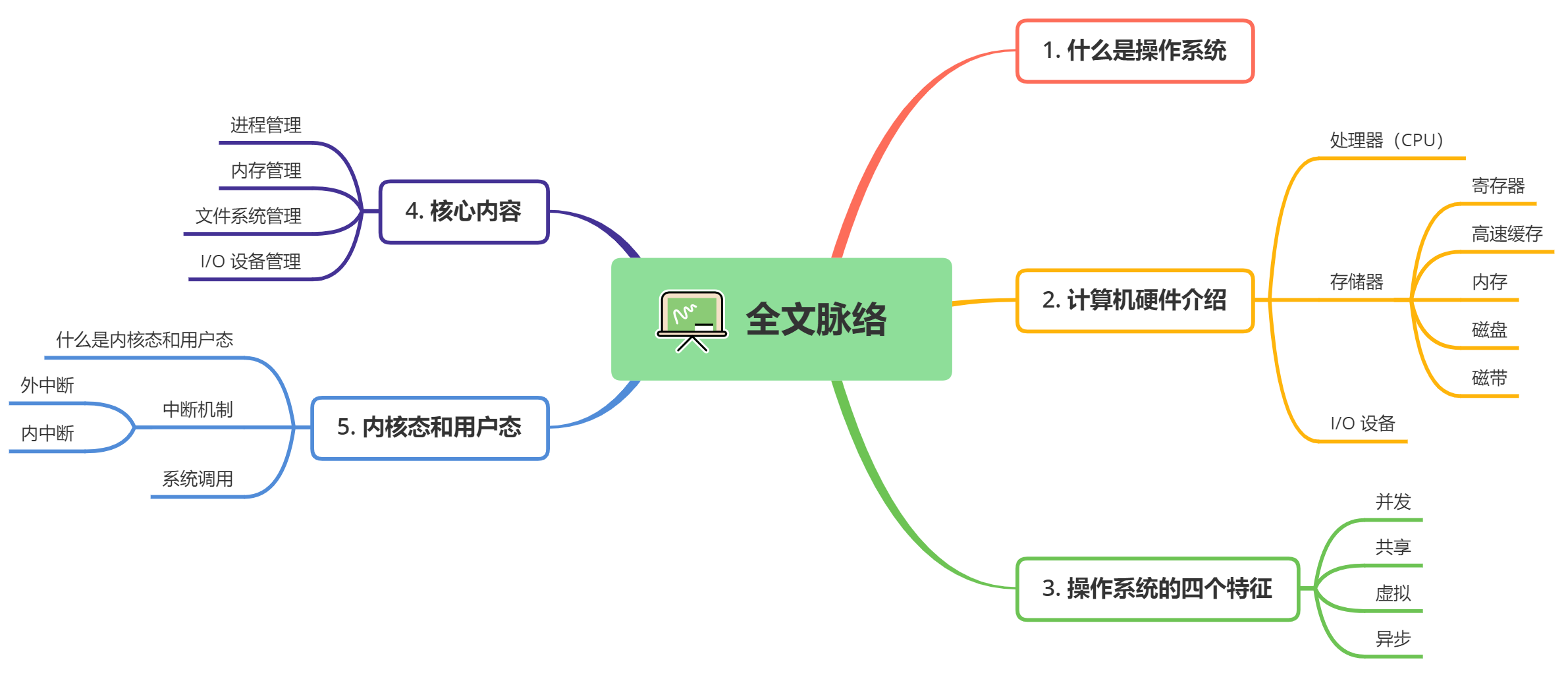
在学习操作系统的过程中,我们会接触到众多复杂的概念,如内核、进程管理、内存管理、文件系统等。为了更好地掌握这些内容,建议采取循序渐进的学习路线,从理论到实践、从基础到进阶,逐步深入。
学习路线
- 操作系统的基本概念与历史
学习操作系统的基础知识,了解其核心功能和发展历史。
操作系统的起源(如 UNIX 的发展、GNU 项目的影响)
现代操作系统的类型及其关系(如 Linux、Windows、macOS) - 操作系统的核心技术
掌握内核、进程、线程、内存管理、文件系统等关键概念。
内核的设计与功能(特别是 Linux 内核的架构)
进程与线程的管理(理解 fork()、进程调度等)
内存管理的机制:MMU 和虚拟内存: 深入理解 MMU 和虚拟内存的工作原理,以及分页技术和地址翻译机制。
页面置换算法: 了解常用的页面置换算法,如 LRU、FIFO 和 LFU。
写时复制 (COW): 掌握 COW 技术的概念和应用,例如在 fork() 中的使用。
字节序 (Endianness): 了解大端序和小端序的区别,以及它们在数据存储和网络传输中的重要性。
内存泄漏: 理解内存泄漏的概念和危害,并学习如何避免内存泄漏。
文件系统的结构与实现(从文件的存储到系统调用) - 进阶专题:并发与多任务处理
理解并发、并行、以及多任务处理在操作系统中的应用。
推荐学习内容:
不同的文件系统类型(FAT、NTFS、ext4、Btrfs)、使用的数据结构(索引节点、目录条目)、日志记录、磁盘调度算法。
进程间通信(IPC)、信号量、锁机制
多线程编程与并发控制(如 pthread 库的使用) - 系统管理工具: 熟悉常用的 Linux 系统管理工具,如 systemd、cron、top/htop、ps、journalctl 和 dmesg。
文件管理工具: 掌握常用的 Linux 文件管理工具,如 ls、cp、mv、rm、find、grep、tar、gzip、bzip2、chmod 和 chown。
文本处理工具: 学习常用的 Linux 文本处理工具,如 vim、nano、sed、awk、cat、less 和 more。
网络工具: 熟悉常用的 Linux 网络工具,如 ifconfig/ip、ping、traceroute、ssh、curl、wget、netstat、ss、iptables 和 nftables。 - DMA 零拷贝: 了解 DMA 零拷贝技术及其在提高文件传输性能方面的作用。
空分复用和时分复用: 理解空分复用和时分复用的概念及其在操作系统中的应用。
多线程/多进程: 学习多线程和多进程的概念,以及它们在解决阻塞问题和提高程序并发性方面的应用。
协程: 了解协程的概念和优势,以及它们与线程的区别
实践为主: 学习 Linux 最重要的是实践,建议你在学习过程中多动手操作,例如在虚拟机或云服务器上安装 Linux 系统 or 实现一个多线程程序,理解线程调度与同步并尝试使用各种命令和工具。
硬件基础
地址空间(address space)表示任何一个计算机实体所占用的内存大小
程序局部性原理:是指程序在执行时呈现出局部性规律,即在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域,具体来说,局部性通常有两种形式:时间局部性和空间局部性。
**时间局部性:**被引用过一次的存储器位置在未来会被多次引用(通常在循环中)。
**空间局部性:**如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
存储器抽象
在计算机中,每个设备以及进程都被分配了一个地址空间。处理器的地址空间由其地址总线以及寄存器决定。地址空间可以分为Flat——表示起始空间位置为0;或者Segmented——表示空间位置由偏移量决定。在一些系统中,可以进行地址空间的类型转换。至于IP地址空间,IPV4协议并没有预见到IP地址的需求量如此之大,32位的地址空间已经无法满足需求了。因此,开发了IPV6协议,支持128位的地址空间 [1] 。
暴露问题
把物理地址暴露给进程会带来下面几个严重问题。第一,如果用户程序可以寻址内存的每个字节,它们就可以很容易地(故意地或偶然地)破坏操作系统,从而使系统慢慢地停止运行。即使在只有一个用户进程运行的情况下,这个问题也是存在的。第二,使用这种模型,想要同时(如果只有一个CPU就轮流执行)运行多个程序是很困难的。在个人计算机上,同时打开几个程序是很常见的(一个文字处理器,一个邮件程序,一个网络浏览器,其中一个当前正在工作,其余的在按下鼠标的时候才会被激活)。在系统中没有对物理内存的抽象的情况下,很难做到上述情景,因此,我们需要其他办法。
为了解决这些问题,现代操作系统使用虚拟内存技术,将物理地址空间抽象成虚拟地址空间,并通过内存管理单元(MMU)来实现地址转换,使得每个进程只能访问自己的虚拟地址空间,从而提高系统的安全性、隔离性和稳定性。
数据加载
OS使用内存从磁盘中取数据的过程通常称为“数据加载”或“页面调度”,涉及操作系统和硬件的协作,以下是这一过程的详细解释:
- CPU与内存的关系
CPU:中央处理器(CPU)无法直接从磁盘读取数据,所有要执行的指令和数据都必须先加载到内存(RAM)中。
- 磁盘与内存之间的数据交换机制
分页机制(Paging):现代操作系统通常采用虚拟内存管理,其中包含分页机制。当某个程序需要访问的数据不在内存中时,操作系统会将所需的数据从磁盘加载到内存。
- 数据从磁盘加载到内存的过程
3.1 虚拟内存与页表
虚拟内存:操作系统将每个进程分配一个虚拟地址空间,这些虚拟地址并不直接对应物理内存,而是通过页表(Page Table)进行映射。
页表:页表记录了虚拟地址与物理内存地址之间的映射关系。当CPU需要访问一个内存地址时,它首先检查页表以找到对应的物理内存地址。
3.2 页错误(Page Fault)
页错误:如果程序访问的内存地址在当前的页表映射中未找到(即不在内存中),则发生页错误。页错误并非错误,而是一个提示操作系统需要从磁盘中加载数据的信号。
处理页错误:当页错误发生时,操作系统会暂停当前进程,并将相应的数据页从磁盘加载到内存,然后更新页表以反映新的映射关系。
3.3 磁盘I/O操作
I/O请求:操作系统向磁盘发出I/O请求以读取特定的数据块。
数据读取:磁盘控制器负责将所需的数据从磁盘读取到内存缓冲区中。这一过程涉及磁盘旋转定位(如果是HDD)或闪存寻址(如果是SSD)。
DMA传输:直接内存访问(DMA)控制器可能用于加速数据传输过程,将数据从磁盘直接加载到内存,而不经过CPU,释放CPU用于其他任务。
3.4 内存更新
内存填充:当数据从磁盘读取到内存后,操作系统将其放入指定的内存位置,并更新页表以反映这一变化。
进程恢复:在内存更新完成后,操作系统恢复原先的进程,重新执行之前因页错误而暂停的指令。
- 缓存与预读取
磁盘缓存:操作系统可能会将从磁盘读取的数据暂时存储在内存中(缓存),以加速后续的访问。若程序在短时间内再次请求同一数据,操作系统可以直接从内存中获取数据,而无需重新访问磁盘。
预读取(Prefetching):操作系统有时会预先从磁盘读取一系列连续的数据块到内存中,预计程序可能会需要这些数据,从而减少后续的I/O操作次数。
- 文件系统和块设备管理
文件系统:操作系统的文件系统负责将文件映射到磁盘上的物理块地址,决定如何将文件内容组织成块并存储在磁盘上。
块设备管理:块设备(如磁盘)的管理程序处理低级别的读写操作,包括将逻辑块地址转换为物理块地址并执行读写。
- 总结
当CPU需要访问不在内存中的数据时,操作系统会通过页表映射、页错误处理、I/O请求、DMA传输、以及缓存等机制,从磁盘中读取数据并加载到内存。这一过程确保程序在物理内存不足以容纳所有数据时,依然能够顺利执行,从而实现虚拟内存的扩展。
虚拟内存为每个进程提供了一个私有的地址空间 每个进程拥有一片连续完整的内存空间 数据不断换入换出外存实现宏观上的大于实际内存的虚拟内存。
- 虚拟地址空间和物理地址空间: 每个应用程序看到的是一组虚拟地址,而不是真正的物理内存地址。操作系统负责将这些虚拟地址映射到物理内存中的实际位置。
- 分页技术: 操作系统将虚拟内存划分成固定大小的页面(通常是4KB),同时也将物理内存划分成相同大小的页框。虚拟页被映射到物理页框,但不一定要将所有虚拟页都加载到物理内存中。
- 页面置换: 当应用程序需要访问一个虚拟页,但该页不在物理内存中时,会触发页面置换。操作系统会根据一定的算法,将一个当前不太可能访问的物理页替换出去,然后将需要的虚拟页加载到这个物理页中。
- 页表: 操作系统维护一个页表,记录虚拟页与物理页的映射关系。当应用程序访问虚拟地址时,操作系统会查询页表,找到对应的物理页。
- 页面调度算法: 操作系统使用不同的算法来决定哪些页应该被替换出物理内存,以便为新的虚拟页腾出空间。一些常见的页面调度算法包括最近最少使用(LRU)、先进先出(FIFO)、最不常用(LFU)等。
虚拟内存的主要优点包括:
- 允许运行比物理内存更大的应用程序。
- 提供了更好的内存管理和分配灵活性。
- 能够使多个应用程序同时运行,而不会发生内存冲突。
- 提供了更好的内存保护,防止一个应用程序影响到其他应用程序的内存空间。
然而,虚拟内存也有一些缺点,比如访问虚拟内存可能会引入一定的性能开销,因为涉及到物理内存和硬盘之间的数据交换。如果系统中同时运行的应用程序过多,可能会导致频繁的页面置换,从而影响性能。
总之,虚拟内存是现代操作系统中重要的内存管理技术,它通过将物理内存和硬盘空间结合起来,使得计算机系统能够更有效地管理内存资源,并支持运行多个应用程序。
一台计算机具有16位地址意味着它可以寻址2^16个不同的地址,因此它的地址总空间为64K(64 kilobytes)
然而,物理内存只有32KB(32 kilobytes)。这意味着,实际上,计算机在物理内存中只能同时存储32KB的数据。
虚拟内存技术可以提供一种机制,允许计算机运行比其物理内存更大的程序。这是通过将部分程序数据存储在磁盘上的虚拟内存中实现的。
以下是一个简单的解释:
- 虚拟内存:
- 计算机上运行的程序可能比物理内存大。为了解决这个问题,操作系统使用虚拟内存技术。程序的地址空间可以分为多个部分,其中一部分被加载到物理内存中,而另一部分存储在磁盘上的虚拟内存中。
- 当程序访问在虚拟内存中的部分时,操作系统会将相应的数据块加载到物理内存中。这种方式允许运行大于物理内存的程序,但可能会导致性能损失,因为频繁的磁盘I/O会比内存访问慢得多。
- 页面交换:
- 当程序访问未加载到物理内存中的虚拟内存页面时,发生页面交换。操作系统可能会将一些当前不使用的物理内存页面(通常是最近未使用的页面)写回到磁盘上的虚拟内存,以便腾出空间来加载被请求的虚拟内存页面。
- 地址翻译:
- 操作系统使用地址翻译机制来将程序中的虚拟地址映射到物理地址。这个映射是由硬件的内存管理单元(MMU)来处理的。MMU负责将虚拟地址转换为物理地址,并确保访问的内存区域是有效的。
分页系统映射
内存管理单元(MMU)管理着地址空间和物理内存的转换,其中的页表(Page table)存储着页(程序地址空间)和页框(物理内存空间)的映射表。一个虚拟地址分成两个部分,一部分存储页面号,一部分存储偏移量。CPU 上的内存管理单元(Memory Management Unit,MMU)就是专门用来进行虚拟地址到物理地址的转换的,不过 MMU 需要借助存放在内存中的页表,而这张表的内容正是由操作系统进行管理的。
页表是一个十分重要的数据结构!
操作系统为每个进程建立了一张页表。一个进程对应一张页表,进程的每个页面对应一个页表项,每个页表项由页号和块号(页框号)组成,记录着进程页面和实际存放的内存块之间的映射关系。
ARM架构
- 模式:
- 用户模式 (usr):这是应用程序运行的模式。
- 系统管理模式 (svc - Supervisor Call):这是内核模式,系统调用通过SWI (Software Interrupt) 指令进入此模式。
- 系统调用:
- 在ARM中,系统调用通常是通过执行
SWI(或新版的SVC) 指令来实现的。这个指令会触发一个软中断,使得CPU从用户模式切换到监督者模式(内核态),并跳转到预定义的中断向量去处理系统调用。
- 在ARM中,系统调用通常是通过执行
x86架构
- Ring级别:
- Ring 0:内核态,拥有最高权限,可以执行任何指令。
- Ring 3:用户态,权限最低,不能执行特权指令。
- 系统调用:
- 在x86架构上,传统上是通过
int 0x80中断实现系统调用的。现代x86 CPU(特别是x86-64)通常使用syscall指令,这是为了提高系统调用的效率。 int 0x80触发一个中断,使得处理器从Ring 3切换到Ring 0,并跳转到中断处理程序,处理系统调用。
- 在x86架构上,传统上是通过
Linux的系统调用和中断处理
- 系统调用的上下文:
- 系统调用的执行是在调用进程的上下文中进行的。这意味着内核代码可以访问该进程的地址空间,执行I/O操作,管理文件等。
- 硬件中断的上下文:
- 硬件中断处理程序运行在中断上下文中,这个上下文与任何特定进程无关。处理中断的代码必须尽快完成,因为中断处理会阻止其他中断的发生(在同一IRQ线上),或者需要特别处理嵌套中断。
- 切换过程:
- 用户态到内核态:通过系统调用接口(如ARM的
SWI或 x86的int 0x80或syscall),或者硬件中断。 - 内核态到用户态:通过特定的返回指令(如x86的
iret),恢复用户态的执行上下文。
- 用户态到内核态:通过系统调用接口(如ARM的
其他细节
- 驱动程序:
- 驱动程序中的函数一部分作为系统调用的一部分执行,另一部分可能在中断处理程序中执行。驱动程序需要精心设计,以处理好在不同上下文中的操作。
- 安全性和稳定性:
- 这种特权级别的分离确保了即使一个用户态的程序崩溃或被恶意攻击,它也不会直接影响到系统的核心功能,保护了操作系统的稳定性和安全性。
通过这种方式,Linux有效地管理了系统资源,提供了安全的环境让应用程序运行,同时保持了对硬件的完全控制。
dma零拷贝
什么是 DMA 技术?简单理解就是,在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务。

上下文切换到成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。 其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的,下面说一下这个过程:
第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。 第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的。 第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然还是由 CPU 搬运的。 第四次拷贝,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运的。
我们回过头看这个文件传输的过程,我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 CPU 资源,大大降低了系统性能。 这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
所以,总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。
写时复制 (Copy-on-Write, COW) 是一种重要的资源管理技术,用于高效地实现可修改资源的复制操作,尤其是在虚拟内存管理和数据结构中应用广泛。
COW 的核心思想:
- 延迟复制: COW 不会立即复制整个资源,而是在需要修改资源时才进行复制。
- 共享只读数据: 在修改之前,多个进程或数据结构可以共享同一份只读数据,节省内存空间和复制时间。
- 按需复制: 只有当某个进程或数据结构需要修改数据时,才会复制一份副本进行修改,其他进程或数据结构不受影响。
COW 在虚拟内存管理中的应用:
- fork() 系统调用: 在类 Unix 操作系统中,
fork()用于创建一个新进程,该进程是父进程的副本。COW 可以显著提高fork()的效率。- 传统 fork(): 需要复制父进程的整个地址空间,耗时且浪费内存。
- COW fork(): 父进程和子进程 initially 共享相同的物理内存页面,这些页面被标记为只读。只有当某个进程需要修改页面内容时,才会复制一份副本进行修改。
What is POSIX?
POSIX 是一套由 IEEE 制定的标准,旨在维护操作系统之间的兼容性。它定义了 API、命令行 shell 和实用程序接口,以确保软件与各种 Unix 变体和其他操作系统兼容。
Key Components of POSIX
- C API Extensions:
- POSIX greatly extends the ANSI C standard with a wide array of APIs for file operations, process and thread management, networking, memory management, and more.
- File Operations: Includes functions like
mkdir,symlink,stat,poll, etc. - Process and Threads: Functions like
fork,execl,wait,pipe,sem_*,shm_*, etc., are essential for process creation, inter-process communication, and synchronization. - Networking: The
socket()API is crucial for network communication. - Memory Management: Functions like
mmap,mlock,mprotect, etc., manage memory allocation, protection, and advice.
- CLI Utilities:
- POSIX defines a set of standard command-line utilities like
cd,ls,echo,mkdir, etc. Many of these utilities are direct shell front-ends for corresponding C API functions. - Major implementations include GNU Coreutils, which provides the majority of these utilities on Linux systems.
- POSIX defines a set of standard command-line utilities like
- Shell Language:
- POSIX standardizes the shell scripting language, which includes variable assignments, command execution, and control structures. The most common implementation in Linux is GNU Bash.
- Environment Variables:
- POSIX specifies standard environment variables like
HOME,PATH, which play a crucial role in the shell and other utilities.
- POSIX specifies standard environment variables like
- Program Exit Status:
- POSIX extends the ANSI C standard by defining specific exit codes, such as 126 (command found but not executable), 127 (command not found), and values greater than 128 indicating termination by a signal.
- Regular Expressions:
- POSIX defines two types of regular expressions: Basic (BRE) and Extended (ERE). These are used in various CLI utilities, such as
grep, and are implemented in C libraries underregex.h.
- POSIX defines two types of regular expressions: Basic (BRE) and Extended (ERE). These are used in various CLI utilities, such as
- Directory Structure and Filenames:
- POSIX specifies aspects of the filesystem, such as the path separator (
/), special directories (.for current directory,..for parent directory), and restrictions on filenames.
- POSIX specifies aspects of the filesystem, such as the path separator (
- Command Line Utility API Conventions:
- POSIX outlines conventions for command-line utilities, such as using `` for standard input,
-to terminate option parsing, and single-letter flags, although these are not strictly enforced by all implementations (e.g., GNU utilities often use long options).
- POSIX outlines conventions for command-line utilities, such as using `` for standard input,
- POSIX ACLs (Access Control Lists):
- Although originally part of POSIX, ACLs were withdrawn but have been implemented in several operating systems, including Linux.
POSIX Compliance and Implementations
- Certified Systems:
- Not all systems are officially certified as POSIX-compliant due to the cost of certification, but many closely follow the standards. Examples of certified systems include macOS (formerly OS X), AIX, HP-UX, and Solaris.
- Most Linux distributions are very compliant with POSIX, although not officially certified.
- Windows and POSIX:
- Windows had limited POSIX support in some professional editions, but this was deprecated in Windows 8. Since 2016, Microsoft introduced the Windows Subsystem for Linux (WSL), which provides a Linux-like environment with system calls, ELF binary execution, and more, bringing Windows closer to POSIX compliance for developer usage.
- Cygwin and MSYS2:
- These are third-party projects that provide substantial POSIX API functionality on Windows. Cygwin offers a large collection of GNU and Open Source tools that provide functionality similar to a Linux distribution on Windows.
- Android:
- While Android is based on the Linux kernel, it does not fully comply with POSIX, primarily because it uses its own libraries and runtime environment (Dalvik/ART) rather than standard Linux libraries like glibc.
POSIX 在确保不同类 Unix 系统之间的互操作性和可移植性方面发挥着关键作用。虽然 Linux 和 macOS 等一些系统密切遵循 POSIX,但 Windows 等其他系统历来对 POSIX 的支持有限,尽管 WSL 等最近的发展已经改进了这一点。对于想要编写跨不同操作系统的可移植且可互操作的代码的开发人员来说,了解 POSIX 至关重要
Linux
Linus Torvalds 创建了前者。后者是全球数百万开发人员之间的协作,涉及GNU 项目, Linux 内核开发团队由 Torvalds 领导, X Window 系统的各种开发人员在过去的 29 年中,以及其他。这就是自由软件基金会要求将使用来自 GNU 项目的软件的完整 Linux 操作系统称为“GNU/Linux”的原因。
Many open source developers agree that the Linux kernel was not designed but rather evolved through natural selection. Torvalds considers that although the design of Unix served as a scaffolding, “Linux grew with a lot of mutations – and because the mutations were less than random, they were faster and more directed than alpha-particles in DNA.”[73] Eric S. Raymond considers Linux’s revolutionary aspects to be social, not technical: before Linux, complex software was designed carefully by small groups, but “Linux evolved in a completely different way. From nearly the beginning, it was rather casually hacked on by huge numbers of volunteers coordinating only through the Internet. Quality was maintained not by rigid standards or autocracy but by the naively simple strategy of releasing every week and getting feedback from hundreds of users within days, creating a sort of rapid Darwinian selection on the mutations introduced by developers.”[74] Bryan Cantrill, an engineer of a competing OS, agrees that “Linux wasn’t designed, it evolved”, but considers this to be a limitation, proposing that some features, especially those related to security,[75] cannot be evolved into, “this is not a biological system at the end of the day, it’s a software system.”
全称GNU/Linux,是一种免费使用和自由传播的类UNIX操作系统,其内核由林纳斯·本纳第克特·托瓦兹于1991年10月5日首次发布,它主要受到Minix和Unix思想的启发,是一个基于POSIX的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的Unix工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。Linux有上百种不同的发行版,如基于社区开发的debian、archlinux,和基于商业开发的Red Hat Enterprise Linux、SUSE、Oracle Linux等。
Linus built kernel to solve unix hard-use and lack I/O RPC function. 区分 Linux(内核)和 Linux(操作系统)。
Kernel 是计算机操作系统核心的计算机程序,通常可以完全控制系统中的所有内容**。**[1]它是操作系统代码的一部分,始终驻留在内存中[2]并促进硬件和软件组件之间的交互。完整的内核通过设备驱动程序控制所有硬件资源(例如 I/O、内存、密码) ,仲裁涉及这些资源的进程之间的冲突,并优化公共资源的利用,例如 CPU 和缓存使用、文件系统和网络套接字。在大多数系统上,内核是启动时最先加载的程序之一(在引导加载程序)。它处理其余的启动以及内存、外围设备和来自软件的输入/输出(I/O) 请求,将它们转换为中央处理器的数据处理指令。
内核是操作系统的核心部分,具有完全控制系统资源的能力。它始终驻留在内存中,促进硬件和软件之间的交互。内核通过设备驱动程序控制硬件资源,仲裁进程之间的冲突,并优化共享资源的利用。在大多数系统上,内核是启动时最先加载的程序。
内核的关键代码被加载到受保护的内核空间中,与应用程序运行的用户空间分离。这种分离可以防止用户数据和内核数据相互干扰,并提高系统的稳定性和安全性。内核提供了一个低级的接口,进程通过系统调用来请求内核服务。
内核架构有整体内核和微内核两种设计。整体内核在单个地址空间中运行,以提高速度;微内核在用户空间中运行大部分服务,以提高灵活性和模块化。Linux内核是整体式的,但也支持模块化,可以在运行时加载和卸载内核模块。
内核负责决定将哪些正在运行的程序分配给处理器,从而执行程序。它是计算机系统的中央组件,控制和管理系统的各个方面。
Linux 操作系统将其运行环境分为两种状态:用户态和内核态。用户态是指应用程序运行的环境,而内核态是指操作系统内核运行的环境。
用户态
用户态(User Mode)是指应用程序运行的环境。在用户态下,应用程序可以使用用户态提供的系统调用接口来请求操作系统服务。用户态的应用程序不能直接访问硬件资源,必须通过系统调用来请求内核态的服务。
用户态的特点:
- 应用程序运行在用户态下
- 不允许直接访问硬件资源
- 必须通过系统调用来请求内核态服务
内核态
内核态(Kernel Mode)是指操作系统内核运行的环境。在内核态下,内核可以直接访问硬件资源,管理系统资源,并提供服务给用户态的应用程序。
内核态的特点:
- 操作系统内核运行在内核态下
- 允许直接访问硬件资源
- 管理系统资源并提供服务给用户态应用程序
系统调用
系统调用(System Call)是用户态应用程序请求内核态服务的接口。用户态应用程序通过系统调用来请求内核态的服务,例如读取文件、创建进程等。
系统调用的过程:
- 应用程序在用户态下执行
- 应用程序需要请求内核态服务
- 应用程序通过系统调用接口请求服务
- 内核态接收到请求并处理
- 内核态将结果返回给应用程序
实践
$表明是非root用户登录,#表示是root用户登录,它们是终端shell的命令提示符 几种常用终端的命令提示符
BASH: root账户: # ,非root账户:
1 | 而/ 是根节点, ~ 是 home |
Program: a file containing instructions to be executed, static Process: an instance of a program in execution, live entity
execve(执行文件)在父进程中fork一个子进程,在子进程中调用exec函数启动新的程序。exec函数一共有六个,其中execve为内核级系统调用,其他(execl,execle,execlp,execv,execvp)exec(): often used after fork() to load another process
许多程序需要开机启动。它们在Windows叫做"服务"(service),在Linux就叫做"守护进程"(daemon)。Linux Daemon(守护进程)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。
- syslogd:系统日志守护进程,负责记录系统日志消息。
- httpd:Web 服务器守护进程,如 Apache 或 Nginx,用于提供 Web 服务。
- sendmail:邮件服务器守护进程,负责处理发送和接收邮件的功能。
- mysqld:数据库服务器守护进程,比如 MySQL 或 MariaDB,用于管理和提供数据库服务。
这些守护进程通常在系统启动时自动启动,并在系统运行期间持续监听、处理或提供服务。它们的运行通常不需要用户的直接干预,而是通过配置文件或其他设置来控制其行为和功能。
FTP
主动模式的FTP是指服务器主动连接客户端的数据端口,被动模式的FTP是指服务器被动等待客户端连接自己的数据端口。
被动模式的FTP通常用在处于防火墙之后的FTP客户访问外界FTP服务器的情况,因为在这种情况下,防火墙通常配置为不允许外界访问防火墙之内的主机,而只允许由防火墙之内的主机发起对外的连接请求。因此,在这种情况下不能使用主动模式的FTP传输,而被动模式的FTP可以良好的工作。
主动模式需要服务器主动向客户端发起连接,而现在普通的客户端大多位于NAT之后,所以主动模式常常无法进行。即使可以,也需要客户端打开防火墙,允许服务端的20端口访问。所以服务端基本需要支持被动模式,但被动模式需要开放一段端口。为了安全,可以选择一小段端口,然后在防火墙开放这一段端口。
Everything is a file
Linux操作系统的设计哲学之一:将所有设备、资源或进程都视为文件或文件类似的对象。
在Linux中,不仅普通的文本文件、目录、硬件设备和外部设备都被视为文件,甚至系统中的进程、网络连接、硬件接口等也被抽象为文件。这种抽象化使得Linux系统更加统一和灵活,因为它允许对不同资源使用相似的操作方式。
好处是读写这些资源都可用open()/close()/write()/read()等函数进行处理。屏蔽了硬件的区别,所有设备都抽象成文件,提供统一的接口给用户。虽然类型各不相同,但是对其提供的却是同一套API。更进一步,对文件的操作也可以跨文件系统执行。在Linux系统中有三类文件:普通文件、目录文件和特殊文件。
网络 I/O 通过网络进行数据传输,通常包括 TCP 或 UDP 等协议。网络 I/O 的延迟较高,取决于网络带宽、路由器、中继设备等,数据包可能需要经过多个中间节点才能到达目标服务器。
局域网的延迟通常在微秒到毫秒级,而广域网(如互联网)的延迟可能会达到几十毫秒甚至更高。网络 I/O 并发是非常常见的需求,特别是在高并发服务器(如 Web 服务器)中。服务器通常需要同时处理数百甚至数千个网络连接。为了提高性能,使用了 I/O 多路复用(select、poll、epoll)和异步 I/O 来管理大量的并发连接。网络 I/O 带宽受到网络设备(如网卡、路由器)的限制。千兆以太网的带宽是 1 Gbps,大约相当于 125 MB/s,而如今常见的 10 Gbps 网卡能达到 1.25 GB/s,远低于本地存储设备。
现代服务器(如 Nginx、Node.js)通常使用异步非阻塞 I/O 模型,以最大限度提高 I/O 吞吐量。
多路复用I/O
select()、poll() 和 epoll() 函数在网络编程和操作系统中用于同时监控多个文件描述符(例如,套接字)的可读性、可写性或异常状态。它们的核心思想是通过监听一组文件描述符,来处理多个输入/输出操作,而不需要每个连接都使用一个独立的线程或进程。它们主要用于事件驱动编程,特别是在服务器中同时处理多个连接时。
1. select()
select() 是一个 POSIX 标准函数,用于监控多个文件描述符,等待其中的某个变为就绪(可读、可写或有异常)。主要应用于网络编程中处理多客户端的并发连接。
用法
1 |
|
nfds: 是需要监控的最大文件描述符加1。readfds: 监控可读事件的文件描述符集合。writefds: 监控可写事件的文件描述符集合。exceptfds: 监控异常事件的文件描述符集合。timeout: 超时参数,指定select()应等待的时间。
使用步骤
- 创建一个
fd_set集合,并通过FD_SET()向其中添加文件描述符。 - 调用
select(),等待文件描述符就绪。 - 检查返回的集合,处理就绪的文件描述符。
例子
1 | fd_set readfds; |
使用场景
- 多客户端 TCP 服务器:在一个进程或线程中,
select()可以同时处理多个客户端的 I/O 请求,而不需要为每个连接创建一个线程。 - 事件驱动系统:通过
select()来处理多个 I/O 事件或定时事件。
2. poll()
poll() 是 select() 的增强版本,解决了 select() 一些性能上的瓶颈(如文件描述符限制)。它更灵活,适合处理大量文件描述符。
1 |
|
fds: 一个结构体数组,每个结构体表示一个文件描述符及其事件。nfds: 要监控的文件描述符数量。timeout: 超时参数,指定等待的时间。
使用步骤
- 创建一个
pollfd数组,为每个文件描述符设置感兴趣的事件。 - 调用
poll(),等待文件描述符就绪。 - 检查返回的结构体数组,处理就绪的文件描述符。
例子
1 | struct pollfd fds[1]; |
使用场景
- 高并发系统:
poll()适用于处理大量并发连接,如高性能 HTTP 服务器。 - 文件描述符大于
select()限制:poll()没有select()的最大文件描述符限制,更适合需要监控大量文件描述符的场景。
3. select() vs poll()
- 性能:
poll()通常比select()更快,尤其是在需要监控大量文件描述符时,因为select()的文件描述符集合在每次调用时都需要重新填充,而poll()使用的pollfd数组更高效。 - 灵活性:
poll()更灵活,支持更多的事件类型,且不受select()最大文件描述符数量的限制。 - 兼容性:
select()是较旧的函数,几乎在所有平台上都支持,而poll()是较新的替代方案,适合更现代的系统。
4. 现代替代方案
epoll()(Linux):比poll()更加高效,特别是在大量文件描述符同时就绪的场景下。适合高并发场景,如大型网络服务器。kqueue()(BSD 系统):FreeBSD、OpenBSD 和 macOS 等系统中的多路复用函数,类似epoll()。
总结
select(): 简单但有文件描述符数量限制,适用于小型并发场景。poll(): 更灵活、适合大量并发连接,解决了select()的一些局限性。
在现代高并发系统中,通常会更倾向于使用 epoll() 或者 kqueue(),而 select() 和 poll() 更多用于相对简单或跨平台的场景。
epoll() (Linux-specific)
-
Usage: A more scalable and efficient mechanism designed specifically for high-performance applications (e.g., handling thousands of file descriptors).
-
Benefits:
- More efficient than
poll()andselect()because it uses an event-based model. - The kernel only returns file descriptors that are ready, rather than polling each one.
- Allows edge-triggered and level-triggered modes, offering flexibility.
- More efficient than
-
Drawbacks:
- Only available on Linux, so it’s not portable to other operating systems like macOS or Windows.
epoll为什么更高效?
- 高效的事件通知机制
- epoll它的工作原理是只向内核注册一次文件描述符(使用epoll_ctl())。此后,内核会跟踪哪些文件描述符已就绪。当您调用时epoll_wait(),它仅返回具有事件(即数据就绪)的文件描述符,而不会扫描所有文件描述符。这使得它更加高效,尤其是在监视大量描述符时,因为它消除了重复扫描的需要。
它不再在每次调用时检查所有文件描述符,epoll而是更像一个“事件驱动”系统:当注册描述符的状态发生变化时,内核会通知您。 epoll()offers two modes: edge-triggered (ET) and level-triggered (LT).- Edge-triggered: The application is notified only once when the state of a file descriptor changes (e.g., when data becomes available). The application is then responsible for reading/writing all available data. This minimizes system calls, as the application doesn’t need to continuously poll the kernel.
- Level-triggered: The behavior is more like
poll()orselect(); it keeps notifying the application as long as the file descriptor remains ready. This provides flexibility, but edge-triggered mode can significantly reduce overhead in high-performance applications.
3. O(1) Performance with Large Numbers of Descriptors
select()andpoll():- Both have O(n) complexity, where
nis the number of file descriptors being monitored. As the number of descriptors grows, the time taken to check them grows linearly.
- Both have O(n) complexity, where
epoll():epoll_wait()has O(1) complexity for most operations, meaning it doesn’t degrade in performance as the number of file descriptors increases. This allows it to scale much better when handling thousands (or even tens of thousands) of connections.
4. Kernel-Space Data Structures
epoll()uses more advanced kernel-space data structures (like red-black trees and linked lists) to efficiently track the file descriptors. Once a file descriptor is registered, it is stored in a tree, allowing quick lookups and updates, further improving performance.- In contrast,
select()andpoll()need to copy all file descriptors from user space to kernel space on every call, and the kernel has to check each one, leading to more overhead.
此外还使用了内存映射(
mmap)技术另一个本质的改进在于
epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的socket描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个socket描述符,一旦检测到epoll管理的socket描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个socket描述符,当进程调用epoll_wait()时便可以得到通知,也就是说epoll最大的优点就在于它 只管就绪的socket描述符,而跟socket描述符的总数无关 。
-
提出一个问题:当在O_APPEND打开后,然后用 lseek移动到其他的位置,然后再用write写,这个时候,请问你数据写到哪里去了?
-
系统调用:
主要使用 open() 系统调用来打开文件。
函数原型:int open(const char *pathname, int flags, mode_t mode);
-
常用标志(flags):
- O_RDONLY:只读模式
- O_WRONLY:只写模式
- O_RDWR:读写模式
- O_CREAT:如果文件不存在则创建
- O_APPEND:追加模式
- O_TRUNC:如果文件存在则清空
- O_NONBLOCK:非阻塞模式
-
权限模式(mode):
当创建新文件时使用,如 0644(所有者可读写,其他人可读)
-
返回值:
成功返回文件描述符(非负整数),失败返回-1
-
文件描述符:
- 是一个小的非负整数
- 用作I/O操作的句柄
- 0, 1, 2 分别预留给标准输入、输出和错误
-
打开文件的限制:
- 每个进程有打开文件的最大数量限制
- 系统全局也有打开文件的最大数量限制
-
关闭文件:
使用 close() 系统调用关闭文件描述符
-
错误处理
使用 errno 来检查具体的错误原因, 在 Linux 中打开和处理文件时,可能会遇到各种问题或错误,这些问题通常与文件系统状态、权限、系统资源限制有关:
- 文件描述符耗尽:
- 原因:打开太多文件而不关闭
- 症状:open() 调用失败,返回 EMFILE 错误
- 解决:及时关闭不用的文件,使用 select()/poll()/epoll() 管理多个文件描述符
- 权限问题:
- 原因:没有足够的权限访问文件
- 症状:open() 返回 EACCES 错误
- 解决:检查文件权限和进程权限,必要时调整
- 文件不存在:
- 原因:尝试打开不存在的文件(未使用 O_CREAT 标志)
- 症状:open() 返回 ENOENT 错误
- 解决:确保文件存在或使用适当的标志创建
- 磁盘空间不足:
- 原因:写入数据时磁盘已满
- 症状:write() 调用失败,返回 ENOSPC 错误
- 解决:清理磁盘空间或使用更大的存储设备
- 文件锁冲突:
- 原因:多个进程同时访问同一文件
- 症状:fcntl() 锁定操作失败
- 解决:实现适当的锁定机制和错误处理
- 符号链接循环:
- 原因:符号链接形成循环
- 症状:open() 返回 ELOOP 错误
- 解决:检查和修复符号链接结构
- 文件系统只读:
- 原因:尝试写入只读文件系统
- 症状:open() 或 write() 返回 EROFS 错误
- 解决:确保文件系统可写或更改操作逻辑
- 文件描述符耗尽:
在 Linux 和类 Unix 系统中,当一个文件以 O_APPEND 模式打开时,每次进行 write 操作时,文件的偏移量都会自动设置到文件的末尾,即使在此之前使用 lseek 改变了文件位置。因此,O_APPEND 标志会导致所有写操作都追加到文件的末尾。
因为 O_APPEND打开后,是一个原子操作:移动到末端,写数据。这是O_APPEND打开的作用。中间的插入时无效的
2.Linux 里利用 grep 和 find 命令查找文件内容
从文件内容查找匹配指定字符串的行:
1 | $ grep "被查找的字符串" 文件名 |
例子:在当前目录里第一级文件夹中寻找包含指定字符串的 .in 文件
1 | grep "thermcontact" /.in |
从文件内容查找与正则表达式匹配的行:
1 | $ grep –e "正则表达式" 文件名 |
查找时不区分大小写:
1 | $ grep –i "被查找的字符串" 文件名 |
fork()
fork() 系统调用,父进程调用fork会创建一个进程副本,代码中还可以通过fork返回值是否为0来区分是子进程还是父进程。子进程与进行 fork() 调用的进程(父进程)同时运行。创建新的子进程后,两个进程都将执行 fork() 系统调用之后的下一条指令。
子进程使用与父进程相同的 pc(程序计数器)、相同的 CPU 寄存器、相同的打开文件。
不同线程,父子拥有独立的内存空间
fork是用来创建子进程的,这个函数的特别之处在于一次调用,两次返回,一次返回到父进程中,一次返回到子进程中,我们可以通过返回值来判断其返回点: 它不接受任何参数并返回一个整数值。下面是 fork() 返回的不同值。
1. fork() 的工作原理
当一个进程调用 fork() 时,操作系统会执行以下操作:
创建子进程:操作系统为子进程分配一个新的进程控制块(PCB),这是操作系统用于管理进程的结构。
复制父进程的资源:
- 子进程会获得父进程的几乎完全相同的资源副本,包括进程的代码段、数据段、堆、栈、文件描述符等。
- 但这只是“写时复制”(Copy-On-Write,COW)的副本,父子进程最初共享相同的内存区域,直到其中一个进程试图修改数据时才会实际进行内存的复制。
返回值:
- 在父进程中,
fork()返回子进程的进程ID(PID)。 - 在子进程中,
fork()返回 0。 - 如果
fork()调用失败(例如系统资源不足),则会返回 -1,并设置errno以指示错误原因。
2. fork() 的使用
以下是一个简单的示例代码,展示了如何使用 fork() 创建一个子进程:
`#include <stdio.h>
#include <unistd.h>
int main() {
pid_t pid = fork(); // 创建子进程
if (pid < 0) { // fork() 调用失败
perror("fork failed");
return 1;
} else if (pid == 0) { // 子进程
printf("This is the child process. PID: %d\n", getpid());
} else { // 父进程
printf("This is the parent process. Child PID: %d, Parent PID: %d\n", pid, getpid());
}
return 0;
}`负值:创建子进程不成功。零:返回新创建的子进程。正值:返回给父级或调用者。该值包含新创建的子进程的进程 ID。
3. fork() 的典型行为
父子进程的执行顺序:
fork()之后,父进程和子进程会继续执行fork()后的代码,但它们的执行顺序是不确定的。父进程可能先执行,也可能子进程先执行。
变量的独立性:
- 尽管子进程复制了父进程的内存空间,但它们的变量是独立的。如果子进程修改了某个变量的值,父进程不会看到这个修改,反之亦然。
文件描述符的共享:
- 子进程复制了父进程的文件描述符表,这意味着父子进程可以访问相同的文件。然而,它们的文件偏移量是共享的;如果一个进程改变了文件的偏移量,另一个进程会受影响。
4. fork() 的典型应用
创建守护进程:fork() 常用于创建守护进程(daemon)。守护进程通常在后台运行,不与终端关联。
多进程服务器:在一个多进程服务器中,服务器进程会 fork() 一个子进程来处理每个客户端请求,从而实现并行处理。
进程隔离:fork() 可以用于创建一个子进程来执行不同的任务,从而实现进程隔离。
5. fork() 相关的其他系统调用
exec() 系列:fork() 通常与 exec() 系列函数(如 execl()、execvp())一起使用。fork() 创建子进程后,子进程可以调用 exec() 来加载一个新的程序。
wait() 和 waitpid():父进程通常通过 wait() 或 waitpid() 等系统调用等待子进程完成。这些调用会阻塞父进程,直到子进程终止,并返回子进程的退出状态。
6. 常见的 fork() 问题
僵尸进程:当一个子进程结束而父进程尚未调用 wait() 或 waitpid() 来读取其退出状态时,子进程会成为僵尸进程,占用系统资源。可以通过父进程调用 `wait
现代替代方案
pthread库:与fork不同,pthread提供了真正的多线程支持,允许多个线程共享同一个进程的地址空间,这在需要高效并发的场景中更加实用。CreateProcess:在 Windows 上,CreateProcess是一个更为灵活的进程创建机制,它提供了比fork更为丰富的选项和功能。
fork只能创建调用该函数的线程的副本,进程中其他运行的线程,fork不予处理。这就意味着,对于多线程程序而言,寄希望于通过fork来创建一个完整进程副本是不可行的。
- 不一致性:如果在多线程环境中使用
fork(),子进程可能会进入一个不一致的状态,因为它只继承了一个线程的状态,而其他线程的状态未被复制。比如,父进程中的某个锁可能正在被另一个线程持有,而子进程中没有这个线程,这可能导致死锁或其他同步问题。 - 资源竞争:多线程程序中,多个线程可能会竞争同一资源(如文件描述符、网络连接等)。当
fork()只复制一个线程时,子进程中的资源状态可能与父进程不一致,导致资源竞争问题。
Best practice
fork()后立即调用exec():在多线程程序中,如果必须使用fork(),通常的做法是在fork()之后立即调用exec()系列函数来启动一个新的程序。这将完全替换子进程的地址空间,避免了与父进程共享资源或状态的不一致性问题。- 使用
pthread_atfork():POSIX 提供了pthread_atfork()函数,用于在fork()调用前后执行特定的准备和恢复操作。通过pthread_atfork(),可以在fork()之前锁定所有全局资源,在子进程中释放这些锁,从而避免潜在的竞争条件。
Libs
- 系统管理
- systemd: 系统和服务管理器
- cron: 定时任务管理
- top/htop: 系统资源监控
- ps: 进程状态查看
- journalctl: 日志查看
- dmesg: 内核日志查看
- 文件管理
- ls, cp, mv, rm: 基本文件操作
- find: 文件搜索
- grep: 文本搜索
- tar, gzip, bzip2: 文件压缩和归档
- chmod, chown: 文件权限管理
- 文本处理
- vim, nano: 文本编辑器
- sed, awk: 文本处理工具
- cat, less, more: 文件查看
- 网络工具
- ifconfig/ip: 网络接口配置
- ping, traceroute: 网络诊断
- ssh: 远程登录
- curl, wget: 文件下载
- netstat, ss: 网络连接状态
- iptables/nftables: 防火墙管理
Systemd 是许多现代 Linux 发行版中使用的初始化系统和系统管理器。以下是关于 systemd 的一些重要概念和常用命令:
- 核心概念:
- Unit:systemd 管理的基本对象,包括服务、挂载点、设备和网络配置等
- Service:最常见的 unit 类型,用于管理守护进程
- Target:一组 unit 的集合,类似于运行级别
Unit 文件结构
一个典型的 .service 单元文件结构如下:
1 | `[Unit] |
注意事项
权限:许多 systemctl 命令需要以 root 权限运行。
配置修改后重载:修改 .service 文件后,需要运行 systemctl daemon-reload 来重新加载配置。
安全性:systemd 提供了许多安全选项,可以限制服务的权限和资源使用。
Endian refers to the order in which bytes are arranged in memory, particularly in multi-byte data types like integers or floating-point numbers. There are two main types of endianess: Big-endian and Little-endian.
- Big-endian: In this format, the most significant byte (the one with the highest address) is stored first. That means the leftmost byte is stored at the lowest memory address. It’s like reading a number from left to right.
- Little-endian: Conversely, in little-endian format, the least significant byte (the one with the lowest address) is stored first. The rightmost byte is stored at the lowest memory address. It’s like reading a number from right to left.
For example, let’s take a 32-bit integer 0x12345678:
- In Big-endian:
- Memory:
12 34 56 78 - Addresses:
0x00 0x01 0x02 0x03
- Memory:
- In Little-endian:
- Memory:
78 56 34 12 - Addresses:
0x00 0x01 0x02 0x03
- Memory:
The choice between big-endian and little-endian is important in systems where data needs to be communicated between different architectures, as interpreting multi-byte data requires knowing the byte order. Some architectures use big-endian (e.g., PowerPC, SPARC), while others use little-endian (e.g., x86, ARM).
- **序列化和反序列化:**将数据结构转换为字节流(序列化)或从字节流重建数据结构(反序列化)时,字节顺序可能会变得相关。序列化库或协议可能会隐式或显式指定或处理字节顺序。
- 网络传输协议通常定义为bigEndian
- 文件读取保存
- **跨平台兼容性:**开发在不同架构上运行的应用程序可能需要注意字节顺序,以确保在系统之间共享数据时数据的一致性和正确性。
许多现代高级编程语言通过提供处理数据表示和转换的标准化方法,在一定程度上抽象了字节顺序问题。例如:
- Python、Java 或 C# 等语言提供了显式处理字节排序的库或方法。在Java中,
java.nio.ByteBuffer类可以用于处理字节顺序。它提供了order()方法,允许你设置字节顺序为大端或小端。 - 序列化库通常在内部处理字节序,将其从开发人员手中抽象出来。
- 标准化网络协议定义了字节顺序约定(例如,HTTP 对某些数据使用大端字节序)。
内存泄漏(Memory Leak):
内存泄漏是指计算机程序中分配的内存空间在不再需要时未被释放,导致系统中的可用内存持续减少。当程序中的内存泄漏严重时,最终可能会导致系统性能下降、程序崩溃甚至系统崩溃。内存泄漏通常由编程错误或设计问题引起,例如忘记释放动态分配的内存、循环引用、指针问题等。为了解决内存泄漏问题,程序员需要定期检查和清理不再使用的内存,或者使用专门的工具来帮助识别和解决内存泄漏。
指针本质上可以在整个OS允许的内存块上任意移动,有时候还会跨界到其他内存块上去。本质上它离机器语言太近,能够造成非常巨大的外延性破坏。一个最经典的例子就是内存践踏造成的缓冲区溢出。
Java语言中没有明确的指针概念,它使用引用(reference)来操作对象。这是为了提高安全性和简化开发,因为指针容易导致内存泄漏、越界访问和悬空指针等问题。Java的对象引用是由Java虚拟机(JVM)管理的,这种方式有助于减少对内存的直接操作,从而提高了安全性和可靠性。
C++ 利用 智能指针达成的效果是:一旦某对象不再被引用,系统刻不容缓,立刻回收内存
一个解决空悬指针的办法是,引入一层间接性,让 p1 和 p2 所指的对象永久有 效。
在Java中,常见的内存泄漏情况包括:
- 长期持有对象的引用: 如果一个对象被分配了内存,并被存储在某个全局变量、静态变量、集合或缓存中,但在后续的程序执行过程中未释放对该对象的引用,即使该对象不再需要,也无法被垃圾回收。
- 监听器未及时移除: 当一个对象作为监听器注册到某个事件上,但在对象不再需要时,未取消注册或者移除对监听器的引用,这可能导致对象无法被垃圾回收。
- 未关闭资源: 例如打开了文件、数据库连接、网络连接等资源,但在使用完后未显式地关闭或释放这些资源,会导致资源泄漏,进而可能导致内存泄漏。
- 循环引用: 当两个或多个对象相互引用,并且这些对象之间形成了一个环形的引用结构,即使这些对象在外部不再被使用,但由于它们互相引用导致它们之间的引用计数不为零,无法被垃圾回收。
为避免内存泄漏,需要进行良好的内存管理和编程实践:
- 及时释放不再需要的对象引用,可以手动将对象引用置为null。
- 在使用完资源后及时关闭文件、数据库连接、网络连接等。
- 避免循环引用,使用弱引用或软引用来避免形成永久性的对象引用。
- 对于监听器等注册的对象,及时取消注册或移除引用。
Golang:
1 | var s0 string // 一个包级变量 |
进程间通信IPC
可选用的6种方法
-
管道 Linux管道是一种特殊的文件描述符的「
|」竖线就是一个管道,它的功能是将前一个命令(ps auxf)的输出,作为后一个命令(grep mysql)的输入,从这功能描述,可以看出管道传输数据是单向的,如果想相互通信,我们需要创建两个管道才行。管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。Channel是Go语言中的一种特殊类型,用于在Goroutine之间进行通信和同步。 -
消息队列(Message Queue):以上三种方式只适合传递传递少量信息,POSIX 标准中 定义了消息队列用于进程间数据量较多小数据的通信。进程可以向队列添加消息,被赋予读权 限的进程则可以从队列消费消息。消息队列克服了信号承载信息量少,管道只能用于无 格式字节流以及缓冲区大小受限等缺点,但实时性相对受限。
-
信号(Signal):信号用于通知目标进程有某种事件发生,除了用于进程间通信外,进 程还可以发送信号给进程自身。信号的典型应用是 kill 命令
kill -l运行在 shell 终端的进程,我们可以通过键盘输入某些组合键的时候,给进程发送信号。例如Ctrl+C 产生SIGINT信号,表示终止该进程; - Ctrl+Z 产生SIGTSTP信号,表示停止该进程,但还未结束; 如果进程在后台运行,可以通过kill命令的方式给进程发送信号,但前提需要知道运行中的进程 PID 号,例如: - kill -9 1050 ,表示给 PID 为 1050 的进程发送
SIGKILL信号,用来立即结束该进程; 所以,信号事件的来源主要有硬件来源(如键盘 Cltr+C )和软件来源(如 kill 命令)。 信号是进程间通信机制中唯一的异步通信机制 -
信号量(Semaphore):为了防止多进程竞争共享资源,互斥和同步问题。信号量就实现了这一保护机制。PV操作,信号量用于两个进程之间同步协作手段,它相当于操作系统提 供的一个特殊变量,程序可以在上面进行 wait() 和 notify() 操作。进程 A 在访问共享内存前,先执行了 P 操作,由于信号量的初始值为 1,故在进程 A 执行 P 操作后信号量变为 0,表示共享资源可用,于是进程 A 就可以访问共享内存。 若此时,进程 B 也想访问共享内存,执行了 P 操作,结果信号量变为了 -1,这就意味着临界资源已被占用,因此进程 B 被阻塞。 直到进程 A 访问完共享内存,才会执行 V 操作,使得信号量恢复为 0,接着就会唤醒阻塞中的线程 B,使得进程 B 可以访问共享内存,最后完成共享内存的访问后,执行 V 操作,使信号量恢复到初始值 1。
-
共享内存(Shared Memory):允许多个进程访问同一块公共的内存空间,这是效率最高的进程间通信形式。原本每个进程的内存地址空间都是相互隔离的,但操作系统提供了让进程主动创建、映射、分离、控制某一块内存的程序接口。当一块内存被多进程共享时,各个进程往往会与其它通信机制,譬如信号量结合使用,来达到进程间同步及互斥的协调操作。
-
套接字接口(Socket)RPc:消息队列和共享内存只适合单机多进程间的通信,套接字接口 是更为普适的进程间通信机制,可用于不同机器之间的进程通信。套接字(Socket)起 初是由 UNIX 系统的 BSD 分支开发出来的,现在已经移植到所有主流的操作系统上。
当仅限于本机进程间通信时,套接字接口是被优化过的,不会经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答等操作,只是简单地将应用层数 据从一个进程拷贝到另一个进程,这种进程间通信方式有个专名的名称:UNIX Domain Socket,又叫做 IPC Socket。
- 只支持半双工通信: 意味着数据传输是单向交替的,通信的一方既是发送者也是接收者,但同一时间只能进行一种操作。
- 仅限于父子进程或兄弟进程之间使用: 由于UNIX Domain Socket是本地通信的一种方式,因此通常用于同一台机器上的进程间通信,比如父子进程或兄弟进程之间。
- 空分复用技术(Swapping): 中。这种技术能够有效地扩展可用内存的大小。空分复用需要快速的内存地址映射,使得操作系统能够迅速将虚拟内存地址转换为实际物理内存地址。这种映射是由CPU中的存储器管理单元(Memory Management Unit,MMU)负责完成的。
- 时分复用技术(Time Division Multiplexing,TDM): 时分复用是一种通信技术,用于多路复用,让多个用户或信号共享同一个通信信道或资源。在操作系统中,时分复用也可以被理解为在单个CPU上执行多个进程的技术。这种技术会分割时间成为多个时间片(Time Slice),每个时间片分配给不同的进程,使得它们轮流占用CPU并执行。这种技术可以使系统中的多个进程表现出并发性,尽管实际上在同一时间点只有一个进程在执行。这种并发性是通过快速的进程切换和调度实现的。
多线程/多进程解决了阻塞问题
线程是抢占式,而协程是非抢占式的,所以需要用户自己释放使用权来切换到其他协程,因此同一时间其实只有一个协程拥有运行权,相当于单线程的能力。
协程并不是取代线程, 而且抽象于线程之上, 线程是被分割的CPU资源, 协程是组织好的代码流程, 协程需要线程来承载运行, 线程是协程的资源, 但协程不会直接使用线程, 协程直接利用的是执行器(Interceptor), 执行器可以关联任意线程或线程池, 可以使当前线程, UI线程, 或新建新程.。
线程是协程的资源。协程通过Interceptor来间接使用线程这个资源。
内核态和用户态
内核kernel是程序,它需要运行,就必须被分配 CPU。因此,CPU 上会运行两种程序,一种是操作系统的内核程序(也称为系统程序),一种是应用程序。前者完成系统任务,后者实现应用任务。两者之间有控制和被控制的关系,前者有权管理和分配资源,而后者只能向系统申请使用资源。
您对内核态(Kernel Mode)和用户态(User Mode)的描述非常准确。以下是进一步的详细解释和一些补充信息:
内核态(Kernel Mode)
- 权限:在内核态中,运行的代码拥有最高的权限,可以访问系统的所有资源,包括硬件和所有内存空间。这意味着内核可以执行任何CPU指令,管理系统的所有硬件资源,如I/O设备、CPU、内存等。
- 用途:
- 系统调用:当用户态的程序需要执行需要高权限的操作(如I/O操作、进程管理等),它通过系统调用陷入内核态。
- 硬件中断处理:硬件中断发生时,系统会切换到内核态来处理中断。
- 内存管理:内核负责管理虚拟内存到物理内存的映射,保护内存空间不被非法访问。
- 风险:由于内核态的代码有如此高的权限,任何错误或漏洞都可能导致系统崩溃或安全性问题。
用户态(User Mode)
- 权限:在用户态,程序的执行权限受到限制。它们只能访问由内核分配和管理的内存空间,并且只能通过系统调用来请求内核执行高权限操作。
- 用途:
- 应用程序执行:所有用户应用程序如浏览器、文本编辑器等都在用户态运行。
- 安全性:限制用户态程序的权限可以保护系统的整体稳定性和安全性,防止一个程序恶意或错误地影响整个系统。
- 内存访问:用户态下的程序只能访问那些在其进程的虚拟地址空间中被映射的内存页。试图访问未映射或无权限的内存会导致保护错误(如段错误)。
- 系统调用:当用户态程序需要进行需要内核权限的操作时(例如读取文件、网络通信等),它必须通过系统调用接口。这时,CPU会切换到内核态,执行相应的内核代码,完成操作后再返回到用户态。
切换机制
- 从用户态到内核态:主要通过以下方式:
- 系统调用(如
fork,exec,read,write等)。 - 中断:如时钟中断,硬件设备中断。
- 异常:如页面错误(page fault),除零错误等。
- 系统调用(如
- 从内核态返回用户态:当内核完成其任务后,通过特定的CPU指令(如在x86架构上的
iret或sysret)返回到用户态,恢复之前的执行上下文。
这种分离的设计有助于系统的稳定性和安全性,因为它限制了用户程序直接操作硬件的能力,从而保护了系统的核心功能不受用户程序的错误或恶意行为影响。
Linux
Linus Torvalds 创建。GNU/LInux是全球数百万开发人员之间的协作,涉及GNU 项目, Linux 内核开发团队由 Torvalds 领导, X Window 系统的各种开发人员在过去的 29 年中,以及其他。这就是自由软件基金会要求将使用来自 GNU 项目的软件的完整 Linux 操作系统称为“GNU/Linux”的原因。
Many open source developers agree that the Linux kernel was not designed but rather evolved through natural selection. Torvalds considers that although the design of Unix served as a scaffolding, “Linux grew with a lot of mutations – and because the mutations were less than random, they were faster and more directed than alpha-particles in DNA.”[73] Eric S. Raymond considers Linux’s revolutionary aspects to be social, not technical: before Linux, complex software was designed carefully by small groups, but “Linux evolved in a completely different way. From nearly the beginning, it was rather casually hacked on by huge numbers of volunteers coordinating only through the Internet. Quality was maintained not by rigid standards or autocracy but by the naively simple strategy of releasing every week and getting feedback from hundreds of users within days, creating a sort of rapid Darwinian selection on the mutations introduced by developers.”[74] Bryan Cantrill, an engineer of a competing OS, agrees that “Linux wasn’t designed, it evolved”, but considers this to be a limitation, proposing that some features, especially those related to security,[75] cannot be evolved into, “this is not a biological system at the end of the day, it’s a software system.”
全称GNU/Linux,是一种免费使用和自由传播的类UNIX操作系统,其内核由林纳斯·本纳第克特·托瓦兹于1991年10月5日首次发布,它主要受到Minix和Unix思想的启发,是一个基于POSIX的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的Unix工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。Linux有上百种不同的发行版,如基于社区开发的debian、archlinux,和基于商业开发的Red Hat Enterprise Linux、SUSE、Oracle Linux等。
Linus built kernel to solve unix hard-use and lack I/O RPC function. 区分 Linux(内核)和 Linux(操作系统)。
Kernel 是计算机操作系统核心的计算机程序,通常可以完全控制系统中的所有内容**。**[1]它是操作系统代码的一部分,始终驻留在内存中[2]并促进硬件和软件组件之间的交互。完整的内核通过设备驱动程序控制所有硬件资源(例如 I/O、内存、密码) ,仲裁涉及这些资源的进程之间的冲突,并优化公共资源的利用,例如 CPU 和缓存使用、文件系统和网络套接字。在大多数系统上,内核是启动时最先加载的程序之一(在引导加载程序)。它处理其余的启动以及内存、外围设备和来自软件的输入/输出(I/O) 请求,将它们转换为中央处理器的数据处理指令。
内核是操作系统的核心部分,具有完全控制系统资源的能力。它始终驻留在内存中,促进硬件和软件之间的交互。内核通过设备驱动程序控制硬件资源,仲裁进程之间的冲突,并优化共享资源的利用。在大多数系统上,内核是启动时最先加载的程序。
内核的关键代码被加载到受保护的内核空间中,与应用程序运行的用户空间分离。这种分离可以防止用户数据和内核数据相互干扰,并提高系统的稳定性和安全性。内核提供了一个低级的接口,进程通过系统调用来请求内核服务。
内核架构有整体内核和微内核两种设计。整体内核在单个地址空间中运行,以提高速度;微内核在用户空间中运行大部分服务,以提高灵活性和模块化。Linux内核是整体式的,但也支持模块化,可以在运行时加载和卸载内核模块。
内核负责决定将哪些正在运行的程序分配给处理器,从而执行程序。它是计算机系统的中央组件,控制和管理系统的各个方面。
Linux 操作系统将其运行环境分为两种状态:用户态和内核态。用户态是指应用程序运行的环境,而内核态是指操作系统内核运行的环境。
用户态
用户态(User Mode)是指应用程序运行的环境。在用户态下,应用程序可以使用用户态提供的系统调用接口来请求操作系统服务。用户态的应用程序不能直接访问硬件资源,必须通过系统调用来请求内核态的服务。
用户态的特点:
- 应用程序运行在用户态下
- 不允许直接访问硬件资源
- 必须通过系统调用来请求内核态服务
内核态
内核态(Kernel Mode)是指操作系统内核运行的环境。在内核态下,内核可以直接访问硬件资源,管理系统资源,并提供服务给用户态的应用程序。
内核态的特点:
- 操作系统内核运行在内核态下
- 允许直接访问硬件资源
- 管理系统资源并提供服务给用户态应用程序
系统调用
系统调用(System Call)是用户态应用程序请求内核态服务的接口。用户态应用程序通过系统调用来请求内核态的服务,例如读取文件、创建进程等。
系统调用的过程:
- 应用程序在用户态下执行
- 应用程序需要请求内核态服务
- 应用程序通过系统调用接口请求服务
- 内核态接收到请求并处理
- 内核态将结果返回给应用程序
实践
Libs
- 系统管理
- systemd: 系统和服务管理器
- cron: 定时任务管理
- top/htop: 系统资源监控
- ps: 进程状态查看
- journalctl: 日志查看
- dmesg: 内核日志查看
- 文件管理
- ls, cp, mv, rm: 基本文件操作
- find: 文件搜索
- grep: 文本搜索
- tar, gzip, bzip2: 文件压缩和归档
- chmod, chown: 文件权限管理
- 文本处理
- vim, nano: 文本编辑器
- sed, awk: 文本处理工具
- cat, less, more: 文件查看
- 网络工具
- ifconfig/ip: 网络接口配置
- ping, traceroute: 网络诊断
- ssh: 远程登录
- curl, wget: 文件下载
- netstat, ss: 网络连接状态
- iptables/nftables: 防火墙管理
Systemd 是许多现代 Linux 发行版中使用的初始化系统和系统管理器。以下是关于 systemd 的一些重要概念和常用命令:
- 核心概念:
- Unit:systemd 管理的基本对象,包括服务、挂载点、设备和网络配置等
- Service:最常见的 unit 类型,用于管理守护进程
- Target:一组 unit 的集合,类似于运行级别
Unit 文件结构
一个典型的 .service 单元文件结构如下:
1 | `[Unit] |
注意事项
权限:许多 systemctl 命令需要以 root 权限运行。
配置修改后重载:修改 .service 文件后,需要运行 systemctl daemon-reload 来重新加载配置。
安全性:systemd 提供了许多安全选项,可以限制服务的权限和资源使用。
$表明是非root用户登录,#表示是root用户登录,它们是终端shell的命令提示符 几种常用终端的命令提示符
BASH: root账户: # ,非root账户:
1 | 而/ 是根节点, ~ 是 home |
Program: a file containing instructions to be executed, static Process: an instance of a program in execution, live entity
execve(执行文件)在父进程中fork一个子进程,在子进程中调用exec函数启动新的程序。exec函数一共有六个,其中execve为内核级系统调用,其他(execl,execle,execlp,execv,execvp)exec(): often used after fork() to load another process
许多程序需要开机启动。它们在Windows叫做"服务"(service),在Linux就叫做"守护进程"(daemon)。Linux Daemon(守护进程)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。
- syslogd:系统日志守护进程,负责记录系统日志消息。
- httpd:Web 服务器守护进程,如 Apache 或 Nginx,用于提供 Web 服务。
- sendmail:邮件服务器守护进程,负责处理发送和接收邮件的功能。
- mysqld:数据库服务器守护进程,比如 MySQL 或 MariaDB,用于管理和提供数据库服务。
这些守护进程通常在系统启动时自动启动,并在系统运行期间持续监听、处理或提供服务。它们的运行通常不需要用户的直接干预,而是通过配置文件或其他设置来控制其行为和功能。
FTP
主动模式的FTP是指服务器主动连接客户端的数据端口,被动模式的FTP是指服务器被动等待客户端连接自己的数据端口。
被动模式的FTP通常用在处于防火墙之后的FTP客户访问外界FTP服务器的情况,因为在这种情况下,防火墙通常配置为不允许外界访问防火墙之内的主机,而只允许由防火墙之内的主机发起对外的连接请求。因此,在这种情况下不能使用主动模式的FTP传输,而被动模式的FTP可以良好的工作。
主动模式需要服务器主动向客户端发起连接,而现在普通的客户端大多位于NAT之后,所以主动模式常常无法进行。即使可以,也需要客户端打开防火墙,允许服务端的20端口访问。所以服务端基本需要支持被动模式,但被动模式需要开放一段端口。为了安全,可以选择一小段端口,然后在防火墙开放这一段端口。
Everything is a file
Linux操作系统的设计哲学之一:将所有设备、资源或进程都视为文件或文件类似的对象。
在Linux中,不仅普通的文本文件、目录、硬件设备和外部设备都被视为文件,甚至系统中的进程、网络连接、硬件接口等也被抽象为文件。这种抽象化使得Linux系统更加统一和灵活,因为它允许对不同资源使用相似的操作方式。
好处是读写这些资源都可用open()/close()/write()/read()等函数进行处理。屏蔽了硬件的区别,所有设备都抽象成文件,提供统一的接口给用户。虽然类型各不相同,但是对其提供的却是同一套API。更进一步,对文件的操作也可以跨文件系统执行。在Linux系统中有三类文件:普通文件、目录文件和特殊文件。
网络 I/O 通过网络进行数据传输,通常包括 TCP 或 UDP 等协议。网络 I/O 的延迟较高,取决于网络带宽、路由器、中继设备等,数据包可能需要经过多个中间节点才能到达目标服务器。
局域网的延迟通常在微秒到毫秒级,而广域网(如互联网)的延迟可能会达到几十毫秒甚至更高。网络 I/O 并发是非常常见的需求,特别是在高并发服务器(如 Web 服务器)中。服务器通常需要同时处理数百甚至数千个网络连接。为了提高性能,使用了 I/O 多路复用(select、poll、epoll)和异步 I/O 来管理大量的并发连接。网络 I/O 带宽受到网络设备(如网卡、路由器)的限制。千兆以太网的带宽是 1 Gbps,大约相当于 125 MB/s,而如今常见的 10 Gbps 网卡能达到 1.25 GB/s,远低于本地存储设备。
现代服务器(如 Nginx、Node.js)通常使用异步非阻塞 I/O 模型,以最大限度提高 I/O 吞吐量。


