1. 环回地址(127.0.0.1)的请求流程
(1) 协议栈的处理
- 数据包仍然会走完整的网络协议栈(应用层 → 传输层 → 网络层 → 链路层),但链路层和物理层的处理是虚拟的。
- 关键点:
- 网络层(IP层): 数据包的目标地址是
127.0.0.1,操作系统识别为环回地址,不会将数据包发送到物理网卡。 - 链路层和物理层: 操作系统通过虚拟的环回接口(
lo或Loopback Adapter)处理数据包,不会触发真实的硬件操作(如网卡收发数据)。 - 传输层(TCP/UDP): 仍然需要完成端口绑定、连接管理等逻辑(例如 TCP 的三次握手)。
- 网络层(IP层): 数据包的目标地址是
(2) 示例:Ping 127.0.0.1
- 当执行
ping 127.0.0.1时:
当你在浏览器、cURL 或任何应用程序(如 ping 127.0.0.1)中输入 127.0.0.1:
应用程序会尝试解析该地址,但 127.0.0.1 是一个 IP 地址,不需要 DNS 解析。
它会选择协议(通常是 TCP 或 UDP),并调用系统 API(如 socket()、connect())。
2. 传输层(Transport Layer)
如果使用 TCP(如 HTTP 请求),应用程序会创建一个 TCP 连接, 内核会生成 TCP 三次握手(SYN -> SYN+ACK -> ACK)。
如果使用 UDP,则不会有连接建立的过程,而是直接发送数据报。
3. 网络层(Network Layer)
传输层将数据交给 网络层,指定目标地址 127.0.0.1。
网络层检测到 127.0.0.1 属于 环回地址(Loopback Address):
这一地址不会被路由到外部网络。
操作系统会将数据包 直接送回本机 处理,而不经过网卡。
a. ICMP 请求(网络层)生成并发送到环回接口。
b. 操作系统直接在内核中将请求转发给接收逻辑,不经过物理网卡。
c. 因此,能 ping 通,但数据包仅在内存中处理,不涉及硬件。
-
127.0.0.1: 是一个 IPv4 地址, 网络层检测到
127.0.0.1属于 环回地址(Loopback Address) -
在支持 IPv6 的系统中,
localhost可能同时映射到127.0.0.1(IPv4)和::1(IPv6)。- 如果服务只监听 IPv4,使用
localhost可能会导致连接失败。
- 如果服务只监听 IPv4,使用
-
性能差异:
- 在大多数情况下,
localhost和127.0.0.1的性能差异可以忽略不计。 - 但在高并发或性能敏感的场景中,直接使用
127.0.0.1可能更高效。
- 在大多数情况下,
2. localhost 的请求流程
localhost是主机名,默认解析为127.0.0.1,因此其行为与直接使用127.0.0.1完全相同。- 请求流程:
- 应用层发起请求(例如访问
http://localhost:8080)。 - DNS 解析将
localhost转换为127.0.0.1。
- 应用层发起请求(例如访问
localhost 的请求处理方式仍然依赖于网络协议栈, 如果 localhost 完全绕过网络协议栈,直接让应用层处理请求,那它确实更像 进程间通信(IPC),比如:
- Unix Domain Socket(UDS)
- 共享内存、管道、消息队列
但实际情况是:
localhost依然需要解析为 IP 地址并走 TCP/IP 协议栈。- 只不过数据不会经过物理网卡,而是在 内核 中完成回环处理。
- 所以它比普通的网络请求快,但比 IPC 方式慢。
3. localhost 请求 vs. 本地进程间通信(IPC)
(1) 相似之处
- 不依赖物理网络: 两者都不需要物理网卡或外部网络设备。
- 高性能: 由于数据在内存中处理,延迟极低。
(2) 关键区别
| 特性 | localhost(环回接口) | 本地进程间通信(IPC) |
|---|---|---|
| 协议栈 | 走完整的网络协议栈(TCP/IP) | 直接通过操作系统提供的 IPC 机制(如管道、共享内存) |
| 编程接口 | 使用 Socket API(如 bind(), listen()) |
使用 IPC 专用 API(如 pipe(), shm_open()) |
| 兼容性 | 与网络通信代码完全兼容 | 需要专门设计 IPC 逻辑 |
| 数据封装 | 需要处理 TCP/UDP 包头、IP 包头等 | 直接传输原始数据 |
| 适用场景 | 模拟网络服务、测试客户端-服务端逻辑 | 高性能进程间数据交换 |
(3) 为什么环回接口仍要走协议栈?
- 兼容性: 开发者可以使用相同的网络编程代码(如 Socket API)测试本地服务,无需修改逻辑。
- 隔离性: 通过端口号隔离不同服务,与远程通信的行为一致。
- 安全性: 防火墙规则可以统一管理环回接口和物理接口的流量。
4. 操作系统的实现优化
- 内核优化: 操作系统会对环回接口的流量进行优化,例如:
- 跳过物理网卡驱动和中断处理。
- 减少数据拷贝次数(如从应用层直接传递到接收缓冲区)。
- 性能对比:
- 环回接口: 延迟通常在微秒级(μs),吞吐量可达数十 Gbps。
- IPC: 延迟可低至纳秒级(ns),吞吐量更高(取决于具体 IPC 机制)。
5. 实验验证
(1) 使用 Wireshark 抓包
- 抓取环回接口(如
Loopback)的流量,可以看到完整的 TCP/IP 数据包(包括以太网帧头),但这些帧头是虚拟生成的,不会发送到物理网卡。
Internet protocol
在当今互联互通的世界中,TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/互联网协议)协议栈构成了现代网络通信的核心。无论是访问网页、发送电子邮件,还是进行视频通话,所有数据的传输都依赖于这一分层协议体系。TCP/IP 协议栈采用分层架构,通常分为四个层次:应用层、传输层、网络层和数据链路层,每一层都承担特定的功能,共同实现可靠、高效的数据传输。网络层(IP)负责寻址和路由,确保数据包能够跨越全球网络到达目标地址;传输层(TCP/UDP)提供数据传输的可靠性和效率,而应用层则承载 HTTP、FTP、DNS 等实际服务,使用户能够便捷地访问互联网资源。
作为现代网络的基石,TCP/IP 协议栈不仅推动了全球互联网的发展,也成为企业网络、云计算、物联网(IoT)等技术的通信标准。它的开放性和可扩展性使其能够不断适应新的技术需求,持续引领数字时代的网络演进。
Protocol defines format,order of messages was sent, received among network entities ,and actions taken on transmission,receipt
OSI
MAC∈datalink LAN层
常见的网络编程中的问题主要是怎么定位网络上的一台主机或多台主机,另一个是定位后如何进行数据的传输。对于前者,在网络层中主要负责网络主机的定位,数据传输的路由,由IP地址可以唯一地确定Internet上的一台主机。对于后者,在传输层则提供面向应用的可靠(tcp)的或非可靠(UDP)的数据传输机制。
对于客户端/服务器(C/S)结构。 即通信双方一方作为服务器等待客户提出请求并予以响应。客户则在需要服务时向服务器提出申请。服务器一般作为守护进程始终运行,监听网络端口,一旦有客户请求,就会启动一个服务进程来响应该客户,同时自己继续监听服务端口,使后来的客户也能及时得到服务。
对于浏览器/服务器(B/S)结构。 客户则在需要服务时向服务器进行请求。服务器响应后及时返回,不需要实时监听端口。
二者的区别,取决于怎么看他们,如果使用浏览器,浏览器就是指“客户端”,“client/server” 和 “browser/server”两种体系结构没有真正的区别,没法比较

HTTP TCP IP
HTTP规定了每段数据以什么形式表达才是能够被另外一台计算机理解。而TCP所要规定的是数据应该怎么传输才能稳定且高效的传递与计算机之间。
HTTP:
200OK 请求成功 400 bad request
Idempotent幂等性概念:幂等通俗来说是指不管进行多少次重复操作,都是实现相同的结果。
2.REST请求中哪些是幂等操作
GET,PUT,DELETE都是幂等操作,而POST不是,以下进行分析:
首先GET请求很好理解,对资源做查询多次,此实现的结果都是一样的。 PUT请求的幂等性可以这样理解,将A修改为B
SSL
SSL(Secure Sockets Layer 安全套接层)是为网络通信提供安全及数据完整性的一种安全协议。SSL 是 “Secure Sockets Layer” 的缩写,中文意思为“安全套接层”,而 TLS 则是标准化之后的 SSL。
TLS
安全传输层协议(TLS:Transport Layer Security)用于在两个通信应用程序之间提供保密性和数据完整性。该协议由两层组成: TLS 记录协议(TLS Record)和 TLS 握手协议(TLS Handshake),是更新、更安全的SSL版本。 HTTPS use TLS1.3
HTTP的核心概念
除了HTTP存在于应用层之外,该协议还有5个特点。
-
HTTP的标准建立在将两台计算机视为不同的角色:客户端和服务器。客户端会向服务器传送不同的请求(request),而服务器会对应每个请求给出回应(response)。无连接
-
HTTP属于无状态协议(Stateless)。这表示每一个请求之间是没有相关性的。在该协议的规则中服务器是不会记录任何客户端操作,每一次请求都是独立的。(记录用户浏览行为会通过其他技术实现)
-
客户端的请求被定义在几个动词意义范围内。最长用到的是GET和POST,其他动词还包括DELETE, HEAD等等。
[GET和POST两种http请求方法的区别]
GET和POST是HTTP请求的两种基本方法, HTTP的底层是TCP/IP。所以GET和POST的底层也是TCP/IP,也就是说,GET/POST都是TCP链接。**GET请求没有body,只有url,请求数据放在url的querystring中;POST请求的数据在body中“。但这种情况仅限于浏览器发请求的场景。**GET和POST能做的事情是一样一样的。你要给GET加上request body,给POST带上url参数,技术上是完全行的通的。
GET
“读取“一个资源。比如Get到一个html文件。反复读取不应该对访问的数据有副作用。比如”GET一下,用户就下单了,返回订单已受理“,这是不可接受的。没有副作用被称为“幂等“(Idempotent)。
因为GET因为是读取,就可以对GET请求的数据做缓存。这个缓存可以做到浏览器本身上(彻底避免浏览器发请求),也可以做到代理上(如nginx),或者做到server端(用Etag,至少可以减少带宽消耗)
- 千万不要用GET方法传送密码等敏感信息!(发出的数据会在浏览器地址栏中显示出来)
POST
在页面里
不幂等也就意味着不能随意多次执行。因此也就不能缓存。比如通过POST下一个单,服务器创建了新的订单,然后返回订单成功的界面。这个页面不能被缓存。试想一下,如果POST请求被浏览器缓存了,那么下单请求就可以不向服务器发请求,而直接返回本地缓存的“下单成功界面”,却又没有真的在服务器下单。那是一件多么滑稽的事情。
因为POST可能有副作用,所以浏览器实现为不能把POST请求保存为书签。想想,如果点一下书签就下一个单,是不是很恐怖?。
POST方法比GET方法更健壮、更安全,而且POST方法对数据大小没有限制。
-
服务器的回应被定义在几个状态码之间:5开头表示服务器错误,4开头表示客户端错误,3开头表示需要做进一步处理,2开头表示成功,1开头表示在请求被接受处理的同时提供的额外信息。
-
不管是客户端的请求信息还是服务器的回应,双方都拥有一块头部信息(Header)。头部信息是自定义,其用途在于传递额外信息(浏览器信息、请求的内容类型、相应的语言)。
持久 or pipeline 连接
**持久连接:**使用同一个TCP连接发送和接受 多个 http请求/应答;
**非持久连接:**一个TCP连接只能发送和接受 一个 http请求/应答;
stateful contains stateless filter, which is the most flexible but cost more.
HTTP2.0 多路复用 (Multiplexing)
多路复用允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息。
pipeline连接
HTTP/1.1的新特性,允许在持久连接上可选地使用请求管道。在响应到达之前,可以将多条请求放入队列。当第一条请求通过网络流向服务器时,第二条和第三条请求也可以开始发送了。在髙时延网络条件下,这样做可以降低网络的环回时间,提高性能。
管道化连接有如下几条限制:
- 客户端必须确认是持久连接才能使用管道;
TCP/IP 意味着 TCP 和 IP 在一起协同工作。TCP 负责应用软件(比如您的浏览器)和网络软件之间的通信。
Internet 的传输层有两个主要协议,互为补充。无连接的是 UDP,它除了给应用程序发送数据包功能并允许它们在所需的层次上架构自己的协议之外,几乎没有做什么特别的事情。面向连接的是 TCP,该协议几乎做了所有的事情。
使用无连接协议可以很方便地支持一对多和多对一通信,而面向连接协议通常都需要多个独立的连接才能做到。但更重要的是,无连接协议是构建面向连接协议的基础。TCP/IP 是基于一个4层的协议栈,如下图所示:
IP 负责计算机之间的通信。TCP 负责将数据分割并装入 IP 包,然后在它们到达的时候重新组合它们。IP 负责将包发送至接受者。
Transport layer
TCP/IP 意味着 TCP 和 IP 在一起协同工作。TCP 负责应用软件(比如您的浏览器)和网络软件之间的通信。
Internet 的传输层有两个主要协议,互为补充。无连接的是 UDP,它除了给应用程序发送数据包功能并允许它们在所需的层次上架构自己的协议之外,几乎没有做什么特别的事情。面向连接的是 TCP,该协议几乎做了所有的事情。
- 使用无连接协议可以很方便地支持一对多和多对一通信,而面向连接协议通常都需要多个独立的连接才能做到。但更重要的是,无连接协议是构建面向连接协议的基础。
IP 负责计算机之间的通信。TCP 负责将数据分割并装入 IP 包,然后在它们到达的时候重新组合它们。IP 负责将包发送至接受者。
Here are some key differences between TCP and UDP:
- Reliability: TCP is a reliable protocol, while UDP is unreliable. TCP provides guaranteed delivery of data packets, ensuring that they arrive at the destination in the correct order and without errors. UDP, on the other hand, does not have built-in mechanisms for error checking, retransmission of lost packets, or ensuring packet ordering. It is up to the application layer to handle these aspects if required.
- Connection-oriented vs. Connectionless: TCP is a connection-oriented protocol, which means it establishes a connection between the sender and receiver before data transmission. It performs a handshake process, establishes a reliable channel, and ensures a secure data transfer. UDP, on the other hand, is connectionless. It does not establish a dedicated connection before data transfer and simply sends packets to the destination without any handshake or setup.
- Packet overhead:开销 TCP has a higher packet overhead compared to UDP. TCP adds additional information to each packet, such as sequence numbers, acknowledgments, and other control flags, which increases the overall size of the transmitted data. UDP has a smaller packet overhead, resulting in less network congestion and lower latency.
- Ordering of packets: TCP guarantees the ordering of packets. If packets arrive out of order, TCP reorders them at the receiver’s end, ensuring that the application layer receives the data in the correct order. UDP does not provide any mechanisms for ordering packets, so the application layer must handle packet ordering if required.
- Flow control and congestion control: TCP implements flow control and congestion control mechanisms to manage the rate of data transmission and avoid network congestion. It dynamically adjusts the transmission rate based on network conditions and ensures that the receiver can handle the incoming data. UDP does not have built-in flow control or congestion control mechanisms, and it’s up to the application layer to manage these aspects if necessary.
- Application suitability: TCP is commonly used for applications that require reliable and ordered data delivery, such as web browsing, email, file transfer, and remote desktop. UDP is suitable for applications that prioritize speed and efficiency over reliability, such as real-time streaming, online gaming, DNS (Domain Name System), and VoIP (Voice over IP).
-
TCP实现细节
https://blog.csdn.net/m0_46156900/article/details/113809699传输层概述、传输层服务、多路复用和解复用、无连接传输 UDP
DEMUX
connectionless: 主机接收到UDP segment (dest port dest IP)
connection oriented:
- 服务器能够在一个TCP端口上同时支持多个TCP套接字:
每个套接字由其四元组标识(有不同的源IP和源PORT) - Web服务器对每个连接客户端有不同的套接字
非持久对每个请求有不同的套接字
“服务器能够根据源IP地址和源端口号来区分来自不同客户机的报文段。
但是套接字与进程之间并非总是有着一一对应的关系。
事实上,Web服务器通常一个服务进程可以为每个新的客户机连接创建一个具有新连接套接字的线程。
显然,对于这样的服务器,在任意给定的时间内都可能有很多套接字(具有不同的标识)连接到同一个进程。”rdt3.0:
具有比特差错和分组丢失的信道
新的假设:****下层信道可能会丢失分组(数据或ACK)(好比之前说的路由器队列排满了,新来的就被drop掉)
- 会死锁
- 机制还不够处理这种状况:
• rdt3.0可以工作,但链路容量比较大的情况下,性能很差 链路容量比较大,一次发一个PDU 的不能够充分利用链路的传输能力 - pipelined protocol
两种通用的流水线协议:回退N步(GBN)和选择重传(SR)
go-back-n的一个缺点 *是单个分组端差错能够引起大量分组端重传,许多分组其实没必要重传。*为了解决这个缺点, selective repeat来了
滑动窗口 (slide window)协议
- 发送缓冲区
形式:内存中的一个区域,落入缓冲区的分组可以发送
功能:用于存放已发送,但是没有未经确认的分组
必要性:需要重发时可用 - 发送缓冲区中的分组
未发送的:落入发送缓冲区的分组,可以连续发送出去;
已发送、等待确认的:发送缓冲区的分组只有得到确认才能删除
selective repeat:
**sender 端:**接收上层端数据,为 分组 assign 序号,如果 在 window 范围内,则发送,同时为每一个分组起一个逻辑定时器,哪个分组端定时器超时,重传哪个分组。上图中, pkt 2 timeout,只重传 pkt2,对其他 package没有影响。
pkt3 发送完会有一个wait的动作,因为现在窗口满了,在收到回复之前不会发送下一个分组。TCP fast retransmit: if the receiver sends triple duplicate ACK for same data, sender resend unacked segment
receiver 端:确认每一个正确接收的分组,而不管是否乱序,乱序端分组被缓存,直到丢失分组(即序号更小的分组)全部接收,将这一批分组按序交付给上层。上图中,收到 pkt1,交付,收到 pkt2,交付,收到pkt3,缓存。
需要注意的是,为什么sender 端在收到ack0 时会立即发送pk4,但是收到ack3时没有继续往外发送数据呢,原因是receiver端发送ACK3时,已经知道pkt2还未到到,所以在ACK3中带端 nextsequence 是pkt2,而此时发送端正在等待pkt2的超时(或者ACK2),所以在pkt2超时之前不会有新端package发出。TCP flow control
receiver controls the sender that sender will not overflow receiver by transmit too much
MTU:
Maximum Transmission Unit,最大数据传输单元,网络传输最大报文包;以太网MTU最大值是1500B
MSS:
Maximum Segment Size ,TCP提交给IP层最大分段大小,不包含TCP Header和 TCP Option,只包含TCP Payload ,MSS是TCP用来限制application层最大的发送字节数。如果底层物理接口MTU= 1500 byte,则 MSS = 1500- 20(IP Header) -20 (TCP Header) = 1460 byte,如果application 有2000 byte发送,需要两个segment才可以完成发送,第一个TCP segment = 1460,第二个TCP segment = 540.要根据MSS的大小进行切分和加TCP头部信息,变成TCP报文段(segment)
·
所以,(Message 转换成字节流,再被划分成一个个的MSS)
MSS+TCP头部信息+IP头部信息 = MTU(比如以太网MTU1500B),(“于是就存在一个分片的问题?”什么分片…)IP分片
在TCP/IP分层中,数据链路层用MTU(Maximum Transmission Unit,最大传输单元)来限制所能传输的数据包大小,MTU是指一次传送的数据最大长度,不包括数据链路层数据帧的帧头。当发送的IP数据报的大小超过了MTU时,IP层就需要对数据进行分片,否则数据将无法发送成功。
一个IP数据报的每个分片都具有自己的IP头部信息,它们都具有相同的标识值,但是具有不同的位偏移,且除了最后一个分片fragflag=0外,其他分片都将设置fragflag=1标志。此外,每个分片的IP头部的总长度字段将被设置为该分片的长度。
例如,以太网帧的MTU是1500字节,因此它的数据部分最大为1480字节(IP头部占用20字节)。
Nagle算法
A problem can occur when an application generates data very slowly.
Consider, ssh or telnet that generate data only when a user types.
This means (for ssh/telnet) one packet sent every time user hits key ——> Nagle’s algorithm\1. 发送 TCP 发送它接收到的第一条数据 - 无论大小
- 发送 TCP 在缓冲区中累积数据并等待以下之一,然后再发送该段: • 接收 TCP 发送确认• 数据已累积以填充最大大小的段
- 重复步骤 2 注意:有时应关闭 Nagle 算法——例如当快速交互至关重要并且您希望发送小数据包时
该算法的优越之处在于它是自适应的,确认到达的越快,数据也就发哦送的越快
Congestion control
- 非正式的定义:“太多的数据需要网络传输,超过了网络的处理能力”
- 拥塞的表现:
- 分组丢失 (路由器缓冲区溢出)
- 分组经历比较长的延迟(在路由器的队列中排队)
速率控制方法
如何控制发送端发送的速率?
(发送方)维持一个拥塞窗口的值:CongWin(CongestionWindow以字节为单位)
它对一个TCP发送方能向网络中发送流量的速率进行了限制。
发送端限制已发送但是未确认的数据量(的上限):
LastByteSent - LastByteAcked <= CongWin
从而粗略地控制发送方的往网络中注入的速率TCP reno : loss indicated by 3 ACKs ;
tcp Tahoe sets cwnd to 1
rate = cwnd/RTT avg TCP throughput = 3Window size /4 RTT
- 服务器能够在一个TCP端口上同时支持多个TCP套接字:
在HTTP的规范内,两台计算机的交互被视为request和response的传递。而在实际的TCP操作中,信息传递会比单纯的传递request和response要复杂。通过TCP建立的通讯往往需要计算机之间多次的交换信息才能完成一次request或response。
TCP的传输数据的核心是在于将数据分为若干段并将每段数据按顺序标记。标记后的顺序可以以不同的顺序被另一方接收并集成回完整的数据。计算机对每一段数据的成功接收都会做出相应,确保所有数据的完整性。
TCP在传递数据时依赖于实现定义好的几个标记(Flags)去向另一方表态传达数据和连接的状态:
- F : FIN - 结束; 结束会话
- S : SYN - 同步; 表示开始会话请求
- R : RST - 复位;中断一个连接 P : PUSH - 推送; 数据包立即发送
- A : ACK - 应答 U : URG - 紧急 E : ECE - 显式拥塞提醒回应
- W : CWR - 拥塞窗口减少
Connection建立& close
也是基于这些标志TCP可以实现三次(three ways handshake)和四次握手 (four ways tear down)。三次握手是初步建立连接的机制,而四次握手则是断开链接。两者之间大致操作是一样的,A发出建立链接(SYN)或者断开链接(FIN)的请求,B认可(A CK)其请求然后发出同样的请求给A并等待A的认可。在双方认可后,链接正式成立或者断开。
!https://img2020.cnblogs.com/blog/2098532/202105/2098532-20210520103027590-619536232.png
!https://img2020.cnblogs.com/blog/2098532/202105/2098532-20210520103048249-324869987.png
1、为什么建立连接协议是三次握手,而关闭连接却是四次握手呢?
建立连接时,ACK和SYN可以放在一个报文里来发送。而关闭连接时,被动关闭方可能还需要发送一些数据后,再发送FIN报文表示同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
2、为什么TIME_WAIT状态还需要等2MSL后才能返回到CLOSED状态?
两个存在的理由:1、无法保证最后发送的ACK报文会一定被对方收到,所以需要重发可能丢失的ACK报文。2、关闭链接一段时间后可能会在相同的IP地址和端口建立新的连接,为了防止旧连接的重复分组在新连接已经终止后再现。2MSL足以让分组最多存活msl秒被丢弃。
3、为什么必须是三次握手,不能用两次握手进行连接?
记住服务器的资源宝贵不能浪费! 如果在断开连接后,第一次握手请求连接的包才到会使服务器打开连接,占用资源而且容易被恶意攻击!防止攻击的方法,缩短服务器等待时间。两次握手容易死锁。如果服务器的应答分组在传输中丢失,将不知道S建立什么样的序列号,C认为连接还未建立成功,将忽略S发来的任何数据分组,只等待连接确认应答分组。而S在发出的分组超时后,重复发送同样的分组。这样就形成了死锁。
QUIC

QUIC 的目标是几乎等同于 TCP 连接,但延迟大大降低。它主要通过依赖于对HTTP流量行为的理解的两项更改来实现这一点。[20]
第一个变化是大大减少连接建立期间的开销。由于大多数 HTTP 连接都需要TLS,QUIC 将设置密钥和支持的协议的交换作为初始握手过程的一部分。当客户端打开连接时,响应数据包包含未来数据包使用加密所需的数据。这消除了建立 TCP 连接然后通过附加数据包协商安全协议的需要。其他协议可以以相同的方式提供服务,将多个步骤组合成一个请求-响应。然后,此数据可用于初始设置中的后续请求,以及将以其他方式协商为单独连接的未来请求。[20]
第二个变化是使用UDP而不是 TCP 作为其基础,其中不包括丢失恢复。相反,每个 QUIC 流都是单独进行流量控制的,丢失的数据在 QUIC 级别而不是 UDP 级别重新传输。这意味着如果一个流中发生错误,如上面的图标示例,协议栈可以继续独立地为其他流提供服务。这对于提高容易出错的链接的性能非常有用,因为在大多数情况下,在 TCP 注意到数据包丢失或损坏之前可能会收到大量额外数据,并且在更正错误时所有这些数据都被阻止甚至刷新。在 QUIC 中,在修复单个多路复用流时,可以自由处理这些数据。[27]
QUIC 还包括许多其他更改,这些更改也可以改善整体延迟和吞吐量。例如,数据包被单独加密,因此它们不会导致加密数据等待部分数据包。这在 TCP 下通常是不可能的,其中加密记录在字节流中,协议栈不知道该流中的高层边界。这些可以由运行在顶层的层协商,但 QUIC 的目标是在一次握手过程中完成所有这些。[8]
QUIC 系统的另一个目标是提高网络切换事件期间的性能,例如当移动设备的用户从本地WiFi 热点移动到移动网络时发生的情况。当这种情况发生在 TCP 上时,一个漫长的过程开始,每个现有的连接一个接一个地超时,然后根据需要重新建立。为了解决这个问题,QUIC 包含一个连接标识符,它可以唯一标识与服务器的连接,而不管来源如何。这允许通过发送始终包含此 ID 的数据包简单地重新建立连接,因为即使用户的IP 地址更改,原始连接 ID 仍然有效。[28]
!https://en.wikipedia.org/w/extensions/ImageMap/resources/desc-20.png?15600
HTTP/3 与 HTTP/1.1 和 HTTP/2 对比的协议栈
QUIC 可以在应用程序空间中实现,而不是在操作系统内核中。当数据在应用程序之间移动时,由于上下文切换,这通常会调用额外的开销。然而,就 QUIC 而言,协议栈旨在供单个应用程序使用,每个使用 QUIC 的应用程序都有自己的连接托管在 UDP 上。最终差异可能非常小,因为整个 HTTP/2 堆栈的大部分已经在应用程序中(或更常见的是它们的库)。将其余部分放在这些库中,本质上是纠错,对 HTTP/2 堆栈的大小或整体复杂性几乎没有影响。[8]
这种组织允许更容易地进行未来的更改,因为它不需要更改内核来进行更新。QUIC 的长期目标之一是添加用于前向纠错(FEC) 和改进拥塞控制的新系统
Network layer
2functions: forwarding 转发: (是一种局部的概念/功能…数据平面的…依赖于路由表…)将分组从路由器的输入接口转发到合适的输出接口
routing: determine the
1.router examines header fields in all IP datagram
路由器
功能
- 运行路由算法/协议(RIP,OSPF,BGP)
- 将数据报从入口链路转发到出口链路
router structure:
ipv6 IP addr 128bits 16bytes
- 实际中的路由器的Router input ports和 output ports 是同一个端口,
- 只是为了方便输入输出端口的讲解才分成两个“独立的输入输出端口”
IP
局域网接入Internet的技术有三种https://blog.csdn.net/wenqiang1208/article/details/72403785:
- 直接路由
- 代理服务器(proxy)代理服务器(Proxy Server)是一种重要的服务器安全功能,它的工作主要在(OSI)模型的会话层,从而起到防火墙的作用。代理服务器大多被用来连接INTERNET(国际互联网)和Local Area Network(局域网)。
代理分类:HTTP代理;socks代理;VPN代理;FTP代理 - 网络地址转换(NAT)NAT将自动修改IP报文的源IP地址和目的IP地址,Ip地址校验则在NAT处理过程中自动完成。有些应用程序将源IP地址嵌入到IP报文的数据部分中,所以还需要同时对报文的数据部分进行修改,以匹配IP头中已经修改过的源IP地址。否则,在报文数据部分嵌入IP地址的应用程序就不能正常工作。
NAT类型:
- NAT0(全锥形NAT): 您的设备拥有一个真实的公网IP地址,可以直接与互联网上的其他设备通信,无需经过额外的转换。这是最理想的网络类型,适合需要高性能和公网访问的应用场景。
- NAT1(对称型NAT): 您的设备可以通过端口映射与互联网上的其他设备通信,但需要手动配置端口映射规则。相对NAT0来说,性能稍差,但仍能满足大多数应用场景的需求。
- NAT2(端口限制型NAT或锥形NAT): 您的设备只能与已建立连接的设备通信,无法主动发起连接。这会限制某些应用的使用,例如P2P下载、部分游戏等。
- NAT3(完全端口限制型NAT): 您的设备只能与已建立连接的设备通信,且只能使用特定的端口。这是限制最严格的NAT类型,会对大部分应用造成影响。
IP (Fragmentation & Reassembly)
网络链路有MTU(最大传输单元) – 链路层帧所携带的最大数据长度 不同的链路类型 不同的MTU
如果IP层有一个数据报要传,而且数据帧的长度比链路层的MTU还大,
那么IP层就需要进行分片( fragmentation),即把数据报分成若干片,这样每一片就都小于MTU。
最后一个分片标记为0 “重组”只在最终的目标主机进行 IP头部的信息被用于标识,排序相关分片
IP(专用)地址 只在局部网络中有意义,区分不同的设备
路由器不对目标地址是专用地址的分组进行转发
专用地址范围(A、B、C类都有)不用向isp申请
!https://img-blog.csdnimg.cn/20210218205701933.png
Class A 10.0.0.0-10.255.255.255 MASK 255.0.0.0
Class B 172.16.0.0-172.31.255.255 MASK 255.255.0.0
Class C 192.168.0.0-192.168.255.255 MASK 255.255.255.0
分类寻址 (Classful Addressing):将 IP 地址分为 ABCDE 五类,三个主要类为 ABC 三类,区别在于网络号和主机号的长度,网络号和主机号的划分线在八位字节边界,如 C 类地址前 24 bits 为网络号,后 8 bits 为主机号。
子网分类寻址 (Subnetted Classful Addressing):在子网寻址系统中,通过从主机号中拿取前端部分 bits 作为子网号,用于识别子网,这将原本的两层划分系统(网络号/主机号)被改为三层划分系统(网络号/子网号/主机号)。
无类寻址 (Classless Addressing):将原始的分类寻址抛开,网络号和主机号可以在任意点划分,不需要像分类寻之中那样划分在八位字节边界。这种方案更加灵活有弹性。
CIDR: Classless InterDomain Routing(无类域间路由)
网络前缀越短,
其地址块所包含的地址数就越多。
而在三级结构的IP地址中,划分子网是使网络前缀变长。
VLSM(可变长子网掩码) 是为了有效的使用无类别域间路由(CIDR)和路由汇聚(route summary)来控制路由表的大小,它是网络管理员常用的IP寻址技术
CIDR无类网络是一种相对于有类网络的网络,无类网络IP地址的掩码是变长的。
在有类网络的基础上,拿出一部分主机ID作为子网ID。
例如:
IP地址为192.168.250.44 子网掩码不能是小于24位。
因为这是一个C类地址(前3Bytes是网络号),子网掩码只能大于24位。
而掩码255.255.248.0(21位)是不符合规定的。
·
如果一个网络中的主机有100台,
那么,可以用子网掩码/25来划分这个C类网络(“192.168.250.0/24”):
划分成192.168.250.0/25 和192.168.250.128/25两个子网。
—主机192.168.250.44/25 属于子网192.168.250.0/25。
Subnet
子网掩码不能单独存在,它必须结合IP地址一起使用。
子网掩码只有一个作用,就是将某个IP地址划分成网络地址和主机地址两部分。
IP地址分配中的几个特定类别,以下是对它们的解释:
- 单播地址(Unicast):
- 单播地址用于一对一通信,表示数据包从一个发送者传输到一个特定的接收者。它是最常见的IP地址类型。
- A、B、C 类地址都是单播地址,分别用于大型网络、中等大小网络和小型网络。
- 组播地址(Multicast):
- 组播地址用于一对多通信,表示数据包从一个发送者传输到一个特定的组中的多个接收者。
- D 类地址是组播地址,用于指示数据流向一组设备。多个主机可以通过加入一个特定的组播组来接收这些数据。
- 广播地址(Broadcast):
- 广播地址用于一对所有通信,在一个子网或局域网中向所有设备发送数据包。
- 在 IPv4 中,广播地址通常是特定的地址,例如全网广播地址为255.255.255.255,用于发送数据包给同一网络中的所有设备。
- E 类地址(Reserved):
- E 类地址是保留地址,用于未来可能的用途。这个地址空间暂时没有分配给特定用途,被保留在IP地址分配方案中。
路由器
功能
- 运行路由算法/协议(RIP,OSPF,BGP)
- 将数据报从入口链路转发到出口链路
结构
输入端口(input port):
- 物理层:接收物理信号,将其转换为bit
- 与数据链路层交互来执行数据链路层功能
- 网络层:查找、转发、排队
- 非集中式的交换:转发表的副本已发送给每个输入端口,因此,转发决策由输入端口在本地完成
- 根据数据报的目的地址,在输入端口内存的转发表中寻找输出端口
- 目标:以线缆一级的速度完成输入端口处理
- 队列:如果数据报达到的速率大于处理速率则需要排队
Input queuing caused by input buffer overflow.
Output port: datagram can be lost due to congestion,lack of buffers(arrive rate fabric > transmission rate).
scheduling discipline: priority scheduling- network neutrality
交换结构fabric 3种:memory, bus,interconnection network
交换结构将路由器的输入端口连接到它的输出端口。这种交换结构包含在路由之中,是一个路由器中的"网络"
输出端口
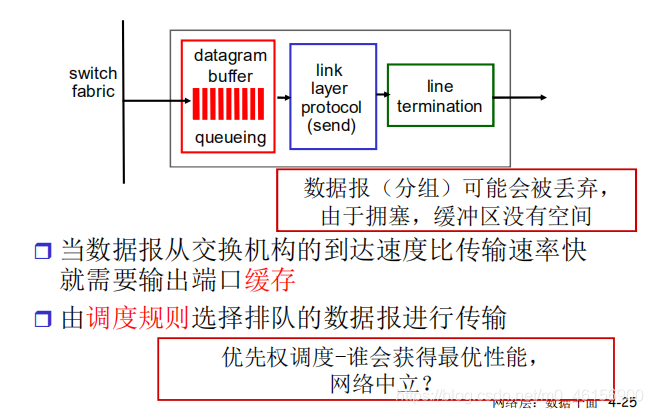
输出端口存储从交换结构接收到的分组,并在输出链路上传输这些分组。当一条链路是双向的时,输出端口常与该链路输入端口成对出现在同一线路卡上。
- 缓冲区:当交换结构速率较快时,就需要缓存,否则,在遇到拥塞时,会导致分组丢失
- 分组调度:先来先服务(FCFS)规则,加权公平排队规则(WFQ),遵循“网络中立”原则,为服务质量保障(QoS)起到关键作用
数据平面、控制平面
control plane methods:
1 traditional router algorithm
2 software-defined networking (SDN): 在远程的服务器中实现
(Compare to the traditional routing algorithm,SDN is much more flexible.
router structure:


- 实际中的路由器的Router input ports和 output ports 是同一个端口,
- 只是为了方便输入输出端口的讲解才分成两个“独立的输入输出端口”
longest prefix matching
TCAM with high speed
scheduling
Priority scheduling
-
Round Robin (RR) scheduling(本意环形丝带,其实叫轮询调度):
Weighted Fair Queuing (WFQ,加权公平队列):
-
FIFO scheduling
IP

局域网接入Internet的技术有三种https://blog.csdn.net/wenqiang1208/article/details/72403785:
-
直接路由
-
代理服务器(proxy)代理服务器(Proxy Server)是一种重要的服务器安全功能,它的工作主要在(OSI)模型的会话层,从而起到防火墙的作用。代理服务器大多被用来连接INTERNET(国际互联网)和Local Area Network(局域网)。
代理分类:HTTP代理;socks代理;VPN代理;FTP代理 -
网络地址转换(NAT)NAT将自动修改IP报文的源IP地址和目的IP地址,Ip地址校验则在NAT处理过程中自动完成。有些应用程序将源IP地址嵌入到IP报文的数据部分中,所以还需要同时对报文的数据部分进行修改,以匹配IP头中已经修改过的源IP地址。否则,在报文数据部分嵌入IP地址的应用程序就不能正常工作。
IP 分片和重组
(Fragmentation & Reassembly)
网络链路有MTU(最大传输单元) – 链路层帧所携带的最大数据长度 不同的链路类型 不同的MTU
如果IP层有一个数据报要传,而且数据帧的长度比链路层的MTU还大,
那么IP层就需要进行分片( fragmentation),即把数据报分成若干片,这样每一片就都小于MTU。
最后一个分片标记为0 “重组”只在最终的目标主机进行 IP头部的信息被用于标识,排序相关分片
IP(专用)地址 只在局部网络中有意义,区分不同的设备
路由器不对目标地址是专用地址的分组进行转发
专用地址范围(A、B、C类都有)不用向isp申请

Class A 10.0.0.0-10.255.255.255 MASK 255.0.0.0
Class B 172.16.0.0-172.31.255.255 MASK 255.255.0.0
Class C 192.168.0.0-192.168.255.255 MASK 255.255.255.0
分类寻址 (Classful Addressing):将 IP 地址分为 ABCDE 五类,三个主要类为 ABC 三类,区别在于网络号和主机号的长度,网络号和主机号的划分线在八位字节边界,如 C 类地址前 24 bits 为网络号,后 8 bits 为主机号。
子网分类寻址 (Subnetted Classful Addressing):在子网寻址系统中,通过从主机号中拿取前端部分 bits 作为子网号,用于识别子网,这将原本的两层划分系统(网络号/主机号)被改为三层划分系统(网络号/子网号/主机号)。
无类寻址 (Classless Addressing):将原始的分类寻址抛开,网络号和主机号可以在任意点划分,不需要像分类寻之中那样划分在八位字节边界。这种方案更加灵活有弹性。
编码CIDR
CIDR: Classless InterDomain Routing(无类域间路由)
网络前缀越短,
其地址块所包含的地址数就越多。
而在三级结构的IP地址中,划分子网是使网络前缀变长。
VLSM(可变长子网掩码) 是为了有效的使用无类别域间路由(CIDR)和路由汇聚(route summary)来控制路由表的大小,它是网络管理员常用的IP寻址技术
CIDR无类网络是一种相对于有类网络的网络,无类网络IP地址的掩码是变长的。
在有类网络的基础上,拿出一部分主机ID作为子网ID。
例如:
IP地址为192.168.250.44 子网掩码不能是小于24位。
因为这是一个C类地址(前3Bytes是网络号),子网掩码只能大于24位。
而掩码255.255.248.0(21位)是不符合规定的。
·
如果一个网络中的主机有100台,
那么,可以用子网掩码/25来划分这个C类网络(“192.168.250.0/24”):
划分成192.168.250.0/25 和192.168.250.128/25两个子网。
—主机192.168.250.44/25 属于子网192.168.250.0/25。
subnet
子网掩码不能单独存在,它必须结合IP地址一起使用。
子网掩码只有一个作用,就是将某个IP地址划分成网络地址和主机地址两部分。
A、B、C类的地址叫做单播地址(unicast)——“我到你”。而D 类地址叫组播地址(multicast)——“我到这个D类组的”…
还以一种叫广播地址(broadcast)——“我到所有”,一般在局域网内部
E 类地址预留的(Reserved for future use) (但存方寸地,留与子孙耕)
在路由信息的通告的过程当中,还不断地做路由聚集。减少表项,路由减负。
路由聚集的作用:

DHCP
第一步:Client通过广播(broadcast)发送DHCP Discover 报文,Look for服务器端
第二步:Server通过单播(unicast)发送DHCP Offer 报文向客户端提供IP地址等网络信息
第三步:Client通过广播DHCP Request 报文告知服务器端本地选择使用哪个IP地址
第四步:Server通过DHCP Ack报文告知客户端IP地址是合法可用的
DHCP返回:ip地址、网关(router、子网掩码、DNS
NAT
network address translation
动机(使用NAT的原因): 本地网络只有一个有效IP地址:
不需要从ISP分配一块地址,可用一个IP地址用于所有的(局域网)设备 –省钱
可以在局域网改变设备的地址情况下而无须通知外界
可以改变ISP(地址变化)而不需要改变内部的设备地址
局域网内部的设备没有明确的地址,对外是不可见的 –安全
- 如果流量从Inside端口进来,那么先执行路由,后执行NAT(本地 到 全局)。
- 如果流量从Outside端口进来,那么先执行NAT(全局 到 本地),后执行路由。
Data plane
a set of match-action rules send by a controller.
traditional: longest prefix match forwarding vs. SDN allows more flexibility
openFlow abstraction: match+action
-
Match,匹配数据包头部
-
Action,根据匹配的结果,做相应的操作,比如修改MAC地址,ACL之类
-
OpenFlow能够启动远程的控制器,经由网络交换器,决定网络数据包要由何种路径通过网络交换机。这个协议的发明者,将它当成软件定义网络(Software-defined networking)的启动器。 [1] OpenFlow允许从远程控制网络交换器的数据包转送表,透过新增、修改与移除数据包控制规则与行动,来改变数据包转送的路径。比起用访问控制表(ACLs) 和路由协议,允许更复杂的流量管理。同时,OpenFlow允许不同供应商用一个简单,开源的协议去远程管理交换机(通常提供专有的接口和描述语言)。
OpenFlow协议用来描述控制器和交换机之间交互所用信息的标准,以及控制器和交换机的接口标准。协议的核心部分是用于OpenFlow协议信息结构的集合。OpenFlow协议支持三种信息类型:Controller-to-Switch,Asynchronous和Symmetric,每一个类型都有多个子类型。Controller-to-Switch信息由控制器发起并且直接用于检测交换机的状态。Asynchronous信息由交换机发起并通常用于更新控制器的网络事件和改变交换机的状态。Symmetric信息可以在没有请求的情况下由控制器或交换机发起。
Control plane
why logically centralized control plane?
控制平面在物理上与转发平面分离,控制软件使用开放接口(例如OpenFlow)对转发平面(例如,交换机和路由器)进行编程。
data plane: mainly forwarding . each router contains a flow table by a centralized routing controller
routing protocol
link state
- 贪心算法 global: all routers have complete topology
Dijkstra算法
condition:any 路径>0 & 单源 已知出发点
/临近,标记!
直到全部点标记结束,回溯找出路径
distance vector
-
距离矢量算法(distance vector routing) 动态规划 decentralized
每个路由器维护一张表(即一个矢量),表中列出了当前已知的到每个目标的最佳距离,以及所用的链路。这些表通过邻居之间交换信息而不断被更新,最终每个路由器都了解到达每个目的地的最佳链路。也叫分布式Bellman-Ford路由算法可以参考:距离矢量算法简介 和 距离矢量算法示例
这个算法存在一个严重的缺陷:虽然它总是能够收敛到正确的答案,但速度可能非常慢。尤其是,它对于好消息的反应非常迅速,而对于坏消息的反应异常迟钝。这个算法存在无穷计数的问题。可扩展性很差,越大的网络收敛的越慢。而且,会占用比较大的网络带宽。
相比于距离矢量算法,链路状态路由算法需要更多的内存和计算,在大型网络中运行这个算法依然是个问题。不过,在许多现实场合,链路状态路由算法工作得非常好,因为它没有慢收敛得问题。
OSPF和IS-IS的出现,许多人认为RIP(distance vector)已经过时了。但事实上RIP也有它自己的优点。对于小型网络,RIP就所占带宽而言开销小,易于配置、管理和实现,并且RIP还在大量使用中。链路状态路由算法被广泛应用于实际网络中。IS-IS,Intermediate System-Intermediate System,被很多的ISP使用。后来它被ISO采纳用于OSI协议;然后它被修改多次以便能够处理多种协议,比如IP协议。OSPF,Open Shortest Path First,是另一个主流的链路状态协议。
AS
Intra-AS routing: aka IGP
OSPF(Open Shortest Path First开放式最短路径优先)是一个内部网关协议(Interior Gateway Protocol,简称IGP),用于在单一自治系统(autonomous system,AS)内决策路由。是对链路状态路由协议的一种实现,隶属内部网关协议(IGP),故运作于自治系统内部。著名的迪克斯彻(Dijkstra)算法被用来计算最短路径树。OSPF支持负载均衡和基于服务类型的选路,也支持多种路由形式,如特定主机路由和子网路由等
inter-AS routing:
job: learn which dests are reachable in other inter-AS system系统间传播(eBGP) ,
and propagate the reachability info to all routers in AS1.内(iBGP)
intra-AS: IGP CONTAIN: RIP OSPF IGRP
BGP inter domain routing protocol
网关就是路由器的IP
SDN control plane
logically centralized : easy management:avoid router mis configurations
ICMP
ICMP enables a router or destination host to communicate with a source host, for example,to report an error in datagram processing. (2 marks)Path MTU discovery uses the Type-3 Destination Unreachable ICMP messages as follows: TCP negotiates initial MTU size – usually TCP/IP sends datagram with Don’t Fragment flag set If datagram is too large an ICMP Destination Unreachable is received Reduce Maximum Transfer Unit.
Internet控制报文协议。它是TCP/IP协议簇的一个子协议,用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。这些控制消息虽然并不传输用户数据,但是对于用户数据的传递起着重要的作用。ICMP使用IP的基本支持,就像它是一个更高级别的协议,但是,ICMP in IP datagram.
above “IP” error reporting and echo request/reply
traceroute (Windows 系统下是tracert) 命令利用ICMP 协议定位您的计算机和目标计算机之间的所有路由器。TTL 值可以反映数据包经过的路由器或网关的数量,通过操纵独立ICMP 呼叫报文的TTL 值和观察该报文被抛弃的返回信息,traceroute命令能够遍历到数据包传输路径上的所有路由器。
Datalink layer
Service
组帧framing,链路接入 link access
封装数据报构成数据帧,加首部和尾部帧同步
如果是共享介质,需要解决信道接入
帧首部的“MAC”地址,用于标识帧的源和目的
- 不同于IP地址
相邻结点间可靠交付
- 在低误码率的有线链路很少采用
流量控制
- 协调相邻的发送结点和接收
差错纠正
- 接收端直接纠正比特差错
全双工和半双工通信控制
- 全双工:链路两端结点同时双向传输
- 半双工:链路两端结点交替双向传输
MAC地址(英语:Media Access Control Address),直译为媒体存取控制位址,也称为局域网地址(LAN Address),MAC位址,以太网地址(Ethernet Address)或物理地址(Physical Address),它是一个用来确认网络设备位置的位址。在OSI模型中,第三层网络层负责IP地址,第二层数据链路层则负责MAC位址 [1] 。MAC地址用于在网络中唯一标示一个网卡,一台设备若有一或多个网卡,则每个网卡都需要并会有一个唯一的MAC地址
循环冗余检验CRC(Cyclic Redundancy Check)
Multiple access protocol
多路访问控制协议
冲突(collision):结点同时接收到两个或者多个信号→接收失败!
MAC协议采用分布式算法决定结点如何共享信道,即决策结点何时可以传输数据。
其必须基于信道本身,通信信道共享协调信息。无带外信道用于协调。
- 信道划分(channel partitioning)MAC协议
TDMA: time division multiple access
TDM 将时间划分为时间帧(timeframe),并进一步划分每个时间帧为N个时隙(slot)
每个站点在每个时间帧,占用固定长度的时隙(长度=分组传输时间);未用时隙空闲(idle)
如图:6站点LAN,134传输分组,256空闲

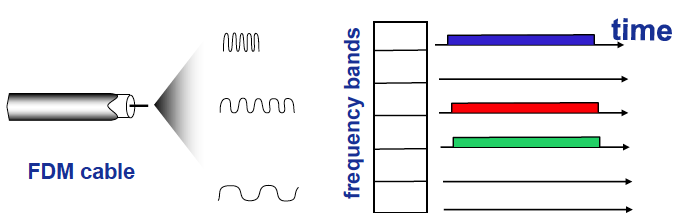
FDMA: frequency division multiple access
信道频谱划分为若干频带(frequency bands)
每个站点分配一个固定的频带,不会冲突但信道利用率可能不高;无传输频带空闲
如图:6站点LAN, 134频带传输数据,256频带空闲。
Random access protocol
包括 ALOHA,CSMA,CSMA/CA,CSMA/CD (transmit entire frame)
Specify 如何检测collision 如何恢复
slotted ALOHA
结点只能在时隙开始时刻发送帧,当结点有新的帧时在下一个时隙(slot)发送如果2个或2个以上结点在同一时隙发送帧,结点即检测到冲突.如果无冲突:该结点可以在下一个时隙继续发送新的帧. 如果冲突:该结点在下一个时隙以概率p重传该帧,直至成功.Slotted aloha reduces the number of collisions to half and doubles the efficiency of pure aloha.
** pure ALOHA**
no synchronization(CLOCK) but only half as efficient as slooted
载波侦听多路访问协议 CSMA(carrier sense multiple access)协议
Listen before transmit
CSMA/CD
easy in wired LAN (ethernet) reduce channel wastage, improve effiency
避免冲突的载波侦听多路访问协议 CSMA/CA(CSMA with Collision Avoidance)协议
802.11无线局域网中,不能像CSMA/CD那样,边发送、边检测冲突,原因为:
(1)检测碰撞的能力要求站点具有同时发送(站点自己的信号)和接收(检测其他站点是否也在发送)的能力。因为在802. 11适配器上,接收信号的强度通常远远小于发送信号的强度,制造具有检测碰撞能力的硬件代价较大。
802.11发送端:
(1)如果监听到信道空闲了分布式帧间间隔DIFS后,则在发送整个帧(发送的同时不检测冲突)
发送端首先利用CSMA向BS发送一个很短的请求发送(request-to-send,RTS)控制帧预约信道,而不是随机发送数据帧,利用小预约帧避免长数据帧的冲突。RTS帧仍然可能彼此冲突(但RTS帧很短)
AP广播一个很短的允许发送(clear-to-send,CTS)控制帧作为对RTS的响应,CTS帧可以被所有结点接收,以消除隐藏站影响
发送端可以发送数据帧,其他结点推迟发送
(2)如果监听到信道忙,则选取随机回退值
当信道空闲时,计时器倒计时; 当计时器超时时,发送帧
(3)如果没有收到ACK,则增加随机退避间隔时间,重复(2)
802.11接收端:
如果正确接收帧,则在延迟短帧间间隔SIFS后,向发送端发送ACK(由于存在隐藏站问题)
ARP
MAC(LAN,or physical or ethernet) address and ARP
48 MAC address in NIC ROM
MAC flat address portable (IP hierarchical not portable)
地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址. PLUG and PLAY
802.11 all use CSMA/CA
LAN

switch
self learning plug and play
frame forwarding, storing ; don’t need to be configured
VLAN
建立逻辑上独立的虚拟网络:于是交换机可以很方便实现虚拟局域网
将连在Switch上的站点更具自己的喜好划分逻辑组:且与物理位置无关
VLAN隔离广播域 :于是也可以对网络安全隔离、控制广播风暴
一般接终端设备使用access port 需要多VLAN透传的使用trunk port
MPLS
是一种在开放的通信网上利用标签引导数据高速、高效传输的新技术。多协议的含义是指MPLS不但可以支持多种网络层层面上的协
goal to fast lookup and borrow ideas from VC
security management
FIrewall
stateless pkt filter, application gateways
stateful contains stateless filter, which is the most flexible but cost more.


